
데이터 스크래핑 3 (API 추출, without Selenium)
이 전에 Selenium으로 데이터를 수집하는 방법을 확인해봤습니다. 이렇게하면 모든 데이터를 다 수집할 수 있을 것 같지만, 이 Selenium에도 단점이 있습니다. 이럴 때 일부 사이트에서 사용 가능한 방법을 소개하겠습니다.
Selenium의 한계
Selenium으로 데이터를 수집할 때 가장 중요한 부분은 정확한 타이밍에 정확한 위치로 찾아가 데이터를 수집하는 것입니다. 따라서 코드를 구현할 때 항상 타이밍 문제가 없도록 해야하고, 여러 번의 클릭을 거쳐 수집해야할 경우 너무 빨리 클릭돼서 문제가 발생하는 일이 없도록 해야합니다. 또한 Selenium 수집의 특성상 수집하는데 시간이 오래걸릴 수 밖에 없습니다. 그래서 일반적으로 Selenium을 사용하는 경우는 최후의 방법이고, 안 쓸 수 있다면 안 쓰는게 좋습니다. 안 쓰는 방법 중 하나가 여기서 소개할 API 추출입니다.
API 추출
CSR(Client Side Rendering) 방식을 사용하는 서버에서는 주로 Template 형태의 페이지를 띄운 후 API를 호출해서 데이터를 채우는 방식을 택합니다. 이 때 사용되는 API를 추출하는 방법은 아래와 같습니다.
우선 크롬 DevTools를 키고 Network 탭을 클릭합니다. 그리고 다른 불필요한 것들이 보이지 않도록 Fetch/XHR을 체크합니다.
 < DevTools Network 화면 >
< DevTools Network 화면 >
그 다음 이 전에 데이터를 수집했던 곳인 바람의나라: 연 커뮤니티의 자유게시판(https://forum.nexon.com/baramy/board_list?board=261)에 접속해봅니다. 아래처럼 몇 가지 결과가 나오는데, 하나 하나 클릭하면서 Preview를 눌러보면 페이지를 구성하기 위해 호출한 API의 데이터를 확인할 수 있습니다. 지금 데이터를 수집하기 위해 필요한 것은 “threads?alias=baramy”으로 시작하는 것입니다. 필요한 것이 무엇인지 확인하려면 하나 하나 클릭해서 필요한 데이터가 있는지 직접 다 확인해봐야합니다. 클릭해서 아래처럼 일치하는 데이터가 찾아지면 잘 찾은 것입니다.
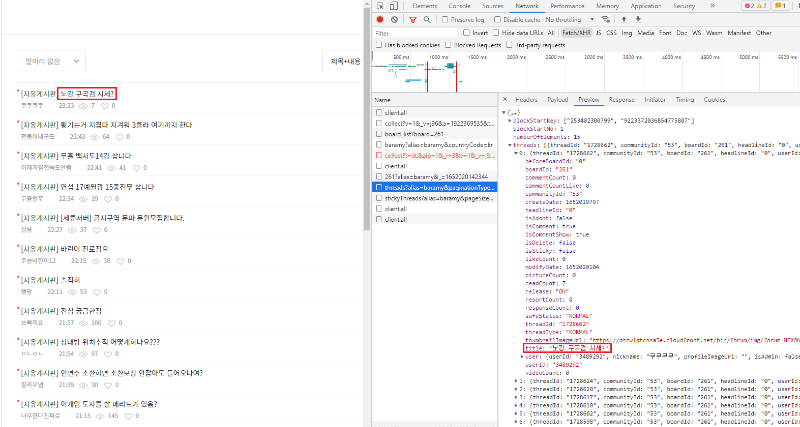 < 글 제목으로 일치하는 데이터 확인 >
< 글 제목으로 일치하는 데이터 확인 >
이제 API를 호출하는 방법을 확인하겠습니다. 아래와 같이 우클릭해서 Copy에 “Copy as cURL (bash)”를 클릭합니다.
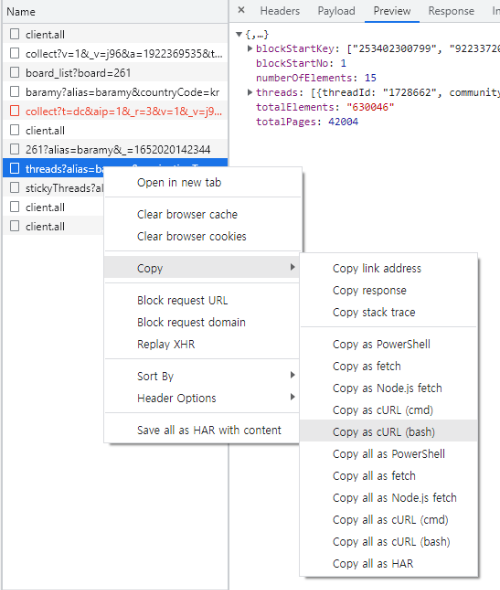
https://curlconverter.com/에 들어가 복사한 내용을 붙여넣습니다. 그러면 API를 호출하는 bash command가 Python 코드로 변환된 것을 확인할 수 있습니다. 변환된 Python 코드를 PyCharm과 같은 툴에 붙여놓고 확인을 위해 아래 코드를 추가로 붙입니다.
...
params = {
'alias': 'baramy',
'paginationType': 'PAGING',
'pageSize': '15',
'pageNo': '1',
'blockSize': '5',
'blockStartKey': [
'253402300799',
'9223372036854775807',
],
'blockStartNo': '1',
'_': '1652020142345',
}
response = requests.get('https://forum.nexon.com/api/v1/board/261/threads', params=params, cookies=cookies, headers=headers)
data = response.json()
for article in data['threads']:
print(article['title'])
이제 코드를 실행해보면 자유게시판에 있는 게시글의 제목이 모두 출력되는 것을 확인할 수 있습니다. 여기서 “params”의 “pageNo”를 1씩 키워가면서 pagination 하듯이 수집할 수 있고, “pageSize” 값을 수정해서 한 번에 수집하는 데이터의 양을 조절할 수도 있습니다.
이 과정을 비슷하게 한번 더 진행하면 게시글의 내용까지 수집할 수 있습니다.
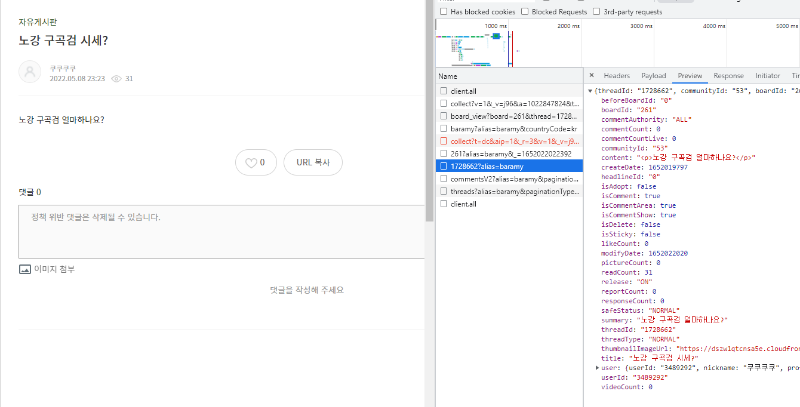
위 사진처럼 게시글을 클릭해보면 게시글을 확인할 수 있는 API가 있고, 동일하게 Python 코드로 변환해서 보면
response = requests.get('https://forum.nexon.com/api/v1/thread/1728662', params=params, cookies=cookies, headers=headers)
이와 같은 코드를 확인할 수 있고 여기서 “1728662”가 게시글의 번호임을 알고 첫 번째 API를 호출해서 게시글 번호를 추출해 활용하면 게시글 내용을 수집할 수 있습니다.
이와 같은 데이터 수집 방식의 장점은 좀 더 유용한 데이터를 추출할 수 있습니다. 예를 들어 “createDate”와 “modifyDate”같이 작성일과 수정일 정보를 수집할수도 있고, “user”에서 유저의 닉네임과 ID 번호, “readCount”와 같은 조회수 등의 내용을 쉽게 수집할 수 있습니다.
이를 통해 Selenium을 사용한 복잡한 코드를 작성하지 않고, Delay 없이 빠르게 데이터를 수집할 수 있습니다. 하지만 이러한 API도 너무 빠르게 수집하면 해당 서버의 트래픽에 부하가 발생할 수 있기 때문에, 문제가 되지 않는 선에서 최대한 여유있게 데이터를 수집하는 것이 좋습니다.
댓글남기기