
데이터 스크래핑 1 (BeautifulSoup)
빅데이터 분석 시스템을 구축할 때 가장 중요한 부분은 데이터 수집입니다. 데이터 수집 방법으로는 DB에 저장되어있는 주기적으로 수집하거나, 제공되는 API를 사용해서 수집할 수 있습니다. 하지만 이러한 방법으로의 수집이 어려울 때, 우리가 웹사이트에서 육안으로 확인할 수 있는 데이터를 수집하고 싶을 때 사용하는 방법이 스크래핑입니다. 여기서는 Python에서 BeautifulSoup을 이용해서 데이터 스크래핑하는 방법을 소개하고, 이후 글에서 다양한 방법의 스크래핑을 소개하겠습니다.
BeautifulSoup
BeautifulSoup을 이용하면 HTML로 되어있는 텍스트를 분석하여 원하는 데이터를 쉽게 추출할 수 있습니다. 아래 예시로 간단하게 확인해보겠습니다.
<ul id="test_list">
<li>연필</li>
<li>지우개</li>
<li>샤프</li>
<li>필통</li>
</ul>
HTML 출력 예시
- 연필
- 지우개
- 샤프
- 필통
위 처럼 웹 페이지에 데이터가 표시되어 있을 때, BeautifulSoup을 이용하면 “test_list”라는 id만 가지고 “연필”, “지우개”, “샤프”, “필통”이라는 데이터를 한 번에 추출할 수 있습니다.
이제 Python 프로젝트를 열어 BeautifulSoup을 설치해봅니다. 가상환경을 잡고 아래 패키지를 설치합니다. 웹 사이트 데이터를 가져오기 위해 requests도 함께 설치합니다.
pip install beautifulsoup4 requests
이제 수집할 사이트를 선정합니다. 여기서는 ITWorld Korea(https://www.itworld.co.kr/)의 뉴스 데이터를 수집해보겠습니다. 데이터를 수집할 때 가장 먼저 확인해야할 것은 이곳의 데이터를 수집해도 괜찮은지를 확인하는 것입니다. 모든 웹 사이트는 robots.txt가 존재하고 여기에 수집에 관련된 규칙이 명시되어있습니다. 도메인 주소 뒤에 robots.txt를 입력하여 확인할 수 있으며 여기서는 https://www.itworld.co.kr/robots.txt로 접속해서 확인이 가능합니다.
...(생략)
User-agent: *
Crawl-delay: 5
Allow: /
Disallow:
# Directories
Disallow: /_connector/
Disallow: /_extension/
Disallow: /download/
Disallow: /print/
# Paths (clean URLs)
Disallow: /node/
Disallow: /admin/
< robots.txt 내용 >
위 내용을 해석해보면 “모든 유저(User-agent: *)는 5초 이상의 주기(Craw-delay: 5)로 전체 경로(Allow: /)의 데이터를 수집할 수 있다.”입니다. 하지만 Allow: /로 되어있어도 아래 Disallow되어있는 경로는 수집하면 안됩니다. 여기 명시되어있는 /_connector/, /_extension/, /download/, /print/, /node/, /admin/으로는 접근하면 안됩니다.
우리가 수집할 데이터는 news 데이터이고, 경로가 /news/(https://www.itworld.co.kr/news/)이기 때문에 수집이 가능합니다. 이제 수집 가능하다는 것을 확인했으니 수집하려는 사이트의 구조를 살펴보겠습니다.
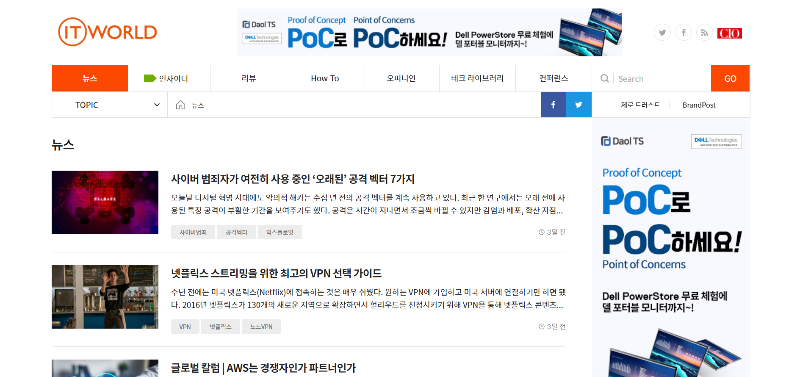 < ITWorld Korea 뉴스 페이지 >
< ITWorld Korea 뉴스 페이지 >
수집하려는 사이트는 위와 같이 되어있습니다. 여기서 Chrome을 이용하여 쉽게 구조를 파악해보겠습니다. Chromium 기반의 브라우저(ex. Edge, 등)면 동일하게 진행이 가능합니다. 먼저 Ctrl + Shift + c를 누릅니다. 그러면 DevTools가 뜨면서 HTML 태그의 위치를 확인할 수 있게 됩니다. 활성화된 상태에서 뉴스 제목을 클릭해보면 아래와 같이 해당 위치의 태그를 확인할 수 있습니다.
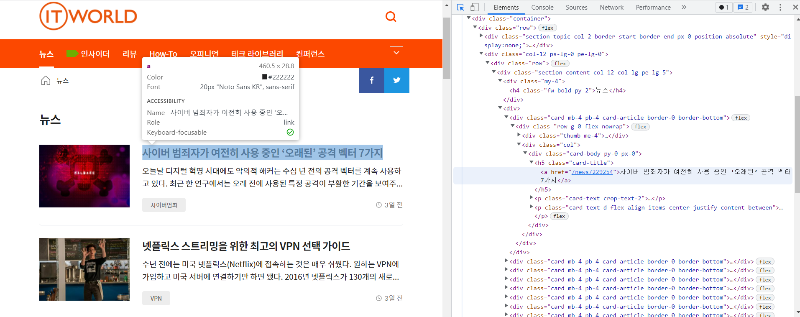 < 뉴스 제목 태그 추출 화면 >
< 뉴스 제목 태그 추출 화면 >
구조를 살펴보면, 각 기사는 card-article이라는 class로 구성돼있고 card와 card-body class를 거쳐 card-title과 card-text에 도달해서 기사의 제목과 내용에 접근할 수 있음을 알 수 있습니다. 이러한 경우 일반적으로 card-title과 card-text만 가지고 정보를 수집할 수 있는데, 정말 그러한지를 확인하기 위해 DevTools의 Console에서 아래와 같이 jQuery 코드를 실행해서 확인해봅니다.
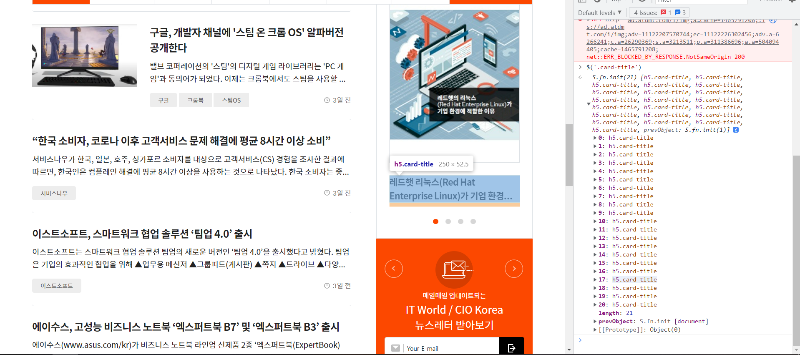 < card-title 추출 결과 >
< card-title 추출 결과 >
$('.card-title')을 실행해서 확인해보면 card-title class만 가지고 추출한 결과 한 페이지에 나오는 기사는 총 17개인데 21개의 class가 추출된 것을 확인할 수 있습니다. 위 결과에서 볼 수 있듯이 17번 인덱스의 card-title은 우측의 다른 곳에서도 사용되고있는데, 이를 해결하기 위해 좀 더 명확하게 추출할 곳을 명시해봅니다.
 < section-content 내 card-title 추출 결과 >
< section-content 내 card-title 추출 결과 >
추출할 기사의 영역이 section-content이기 때문에 section-content안에 있는 card-title을 추출하도록 $('.section-content .card-title')을 실행합니다. 이제 추출하고자 했던 17개의 기사 제목이 추출된 것을 확인할 수 있습니다. card-text도 위와 같은 방식으로 확인해보면 되는데, card-text의 경우 하나의 card 안에 2개씩 사용되고있기 때문에 같이 사용된 crop-text-2를 가지고 추출($('.section-content .crop-text-2'))해서 동일하게 17개가 추출되는 것을 확인합니다.
이제 Python에서 BeautifulSoup을 통해 추출을 해보겠습니다. 먼저 requests를 이용해 페이지의 HTML을 가져옵니다.
import requests
from bs4 import BeautifulSoup
resp = requests.get('https://www.itworld.co.kr/news/')
print(resp.status_code, resp.text)
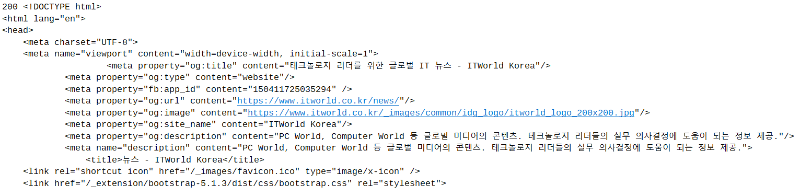 < 출력 결과 >
< 출력 결과 >
위 코드를 통해 해당 주소에 접근해 결과를 잘 가져왔는지(status_code)와 가져온 내용(text)를 확인할 수 있습니다. 이제 위에서 했던 것 처럼 기사의 제목과 내용을 추출해보겠습니다.
soup = BeautifulSoup(resp.text, 'html.parser')
title_list = soup.select('.section-content .card-title')
for title in title_list:
print(title.get_text().strip())
 < 출력 결과 >
< 출력 결과 >
select에 먼저 추출해볼 때 사용했던 내용을 그대로 넣습니다. 그러면 <a> 태그가 포함된 내용이 전부 추출되는데, get_text() 함수로 기사 제목인 텍스트만 추출하고, 기사 뒤에 개행 문자(\n)가 포함되어있기 때문에 strip() 함수로 뒷 공백을 없애줍니다. 이로써 기사 내용을 추출할 수 있습니다.
기사 내용도 위와 동일하게 추출합니다. 위의 추출하는 코드에 내용을 조금 추가해서 확인합니다.
soup = BeautifulSoup(resp.text, 'html.parser')
title_list = soup.select('.section-content .card-title')
content_list = soup.select('.section-content .crop-text-2')
for title, content in zip(title_list, content_list):
print('------------------- article -----------------------')
print(title.get_text().strip())
print(content.get_text().strip())
print('---------------------------------------------------')
 < 출력 결과 >
< 출력 결과 >
이렇게 기사의 제목과 내용을 추출해서 확인할 수 있습니다. 이러한 방식으로 사이트의 페이지를 바꿔가며 내용을 수집할 수 있으며, 추출한 기사의 번호 혹은 날짜를 기준으로 새로운 기사만 주기적으로 수집할 수 있습니다.
다음에는 이 BeautifulSoup만 가지고는 데이터를 수집할 수 없는 경우가 존재하는데, 이때 사용하는 Selenium 기반의 데이터 스크래핑 방법에 대해 이야기하겠습니다.
댓글남기기