
데이터 스크래핑 2 (Selenium)
앞의 게시글에서 설명했던 BeautifulSoup만 사용했을 때 데이터가 수집되지 않는 경우가 있습니다. 이럴 때 사용하는 프레임워크인 Selenium을 이용한 수집 방법을 소개하겠습니다.
BeautifulSoup만 사용할 경우의 한계
BeautifulSoup은 HTML 형태의 plain text에서 특정 데이터를 추출할 수 있는 라이브러리입니다. 따라서 BeautifulSoup으로 데이터를 추출하기 위해 웹 페이지의 내용을 먼저 가져와야합니다. 이전에는 python의 requests를 이용해서 가져왔는데, 아래 예시를 통해 가져올 수 없는 경우를 확인하겠습니다.
아래는 바람의나라: 연 커뮤니티의 자유게시판 글을 수집하는 예시입니다. 먼저 자유게시판(https://forum.nexon.com/baramy/board_list?board=261)으로 들어가서 게시글을 수집할 수 있는 id 혹은 class를 확인합니다.
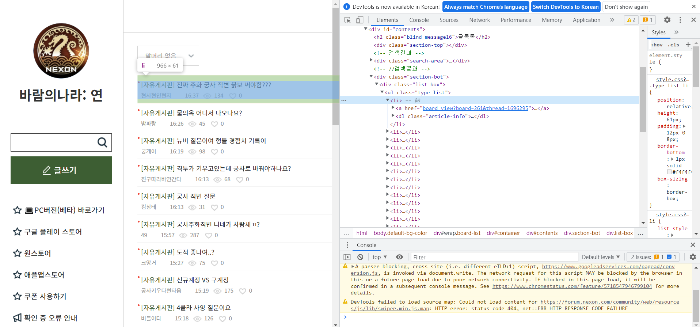 < 바람의나라: 연 커뮤니티 자유게시판 게시글 태그 확인 >
< 바람의나라: 연 커뮤니티 자유게시판 게시글 태그 확인 >
위를 통해 type-list class를 이용해 데이터를 수집할 수 있음을 알 수 있습니다. 이제 기존 방식대로 수집해보겠습니다.
import requests
from bs4 import BeautifulSoup
resp = requests.get('https://forum.nexon.com/baramy/board_list?board=261')
print(resp.text)
soup = BeautifulSoup(resp.text, 'html.parser')
article_list = soup.select('.type-list')
print(article_list)
위 코드를 실행해보면 response text는 잘 출력되지만 article_list는 비어있는 것을 확인할 수 있습니다. 이것은 javascript를 끄고 웹 페이지에 접속해보면 이해할 수 있습니다. 크롬 DevTools가 켜진 상태에서 F1을 누르고 스크롤을 내려 Debugger에서 Disable JavaScript를 체크하고 새로고침합니다.
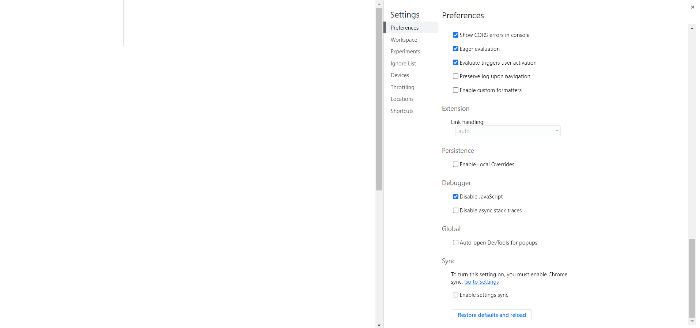 < Disable JavaScript 후 페이지 >
< Disable JavaScript 후 페이지 >
위 처럼 빈 껍데기만 남고 내용이 나오지 않는 것을 확인할 수 있습니다. 이것은 해당 서버에서 CSR(Client Side Rendering) 방식을 사용중이기 때문인데, 간단하게 얘기하면 웹 페이지를 호출하면 처음엔 빈 껍데기만 보내줘서 빠르게 페이지를 띄워주고 나머지 내용을 이후에 JavaScript를 이용해서 채운다고 생각하면 됩니다. 일반적인 웹 페이지 호출 시 JavaScript를 이용해서 채워지는 내용은 가져올 수 없기 때문에, 이럴 때 Selenium을 사용해야합니다.
Selenium
Selenium은 실제 웹 드라이버를 이용해서 웹 페이지가 완전하게 로딩된 이후의 데이터를 수집, 이벤트 발생 등을 할 수 있습니다. 우선 Chrome Driver를 설치해야하는데, chrome://settings/help 여기서 지금 사용중인 Chrome 버전을 확인합니다.
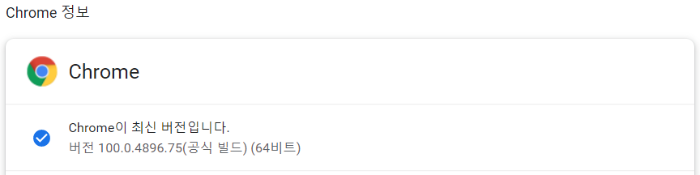 < Chrome 버전 확인 >
< Chrome 버전 확인 >
이제 사용중인 버전에 맞는 Chrome Driver를 설치하면되는데, 저는 사용중인 100.x 버전에 맞는 버전으로 설치하겠습니다. Chrome Driver는 https://chromedriver.chromium.org/downloads여기서 맞는 버전을 찾아 윈도우의 경우 chromedriver_win32.zip으로 다운받으면 됩니다. 그리고 압축을 불고 python 프로젝트 폴더로 옮깁니다.
이제 Selenium을 설치하고 코드를 실행해보겠습니다. Selenium은 터미널에서 pip install selenium을 입력해서 설치합니다. 그리고 아래 코드를 실행해봅니다.
from selenium import webdriver
driver = webdriver.Chrome('chromedriver.exe')
driver.get("https://forum.nexon.com/baramy/board_list?board=261")
driver.implicitly_wait(10)
article_list_ul = driver.find_element_by_class_name('type-list')
article_list_li = article_list_ul.find_elements_by_tag_name('li')
for article in article_list_li:
title = article.find_element_by_tag_name('h3').text
writer = article.find_element_by_class_name('writer').text
link = article.find_element_by_tag_name('a').get_attribute('href')
print(title, writer, link)
위 코드에 대해서 간단하게 설명하면 driver.implicitly_wait(10)는 페이지가 로딩되기까지 최대 10초간 기다린다는 함수입니다. 페이지가 전부 로딩되기 전에 데이터를 가져오면 데이터가 없는 상태이기 때문에 위 함수를 이용해야합니다. 최대 10초인 이유는 페이지 로딩이 완료되면 10초가 지나지 않아도 다음 step으로 넘어갑니다.
driver를 이용해서 BeautifulSoup과 유사하게 데이터를 탐색하는데, 함수 이름의 element와 elements가 다르므로 오타가 발생하지 않도록 주의합니다. 위 처럼 코드를 작성하면 ‘type-list’의 li list를 가져와서 필요한 데이터만 뽑아올 수 있습니다. 실행해보면 아래와 같은 결과가 나오는 것을 확인할 수 있습니다.
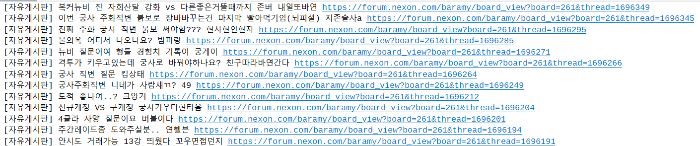 < 코드 실행 결과 일부 >
< 코드 실행 결과 일부 >
이렇게하면 페이지 하나에 표시된 15개의 게시글을 수집할 수 있습니다. 전체 페이지의 글을 수집하기 위해서는 아래 코드를 추가해야합니다. 최종 코드는 아래와 같습니다.
import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
driver = webdriver.Chrome('chromedriver.exe')
driver.get("https://forum.nexon.com/baramy/board_list?board=261")
driver.implicitly_wait(10)
while True:
article_list_ul = driver.find_element_by_class_name('type-list')
article_list_li = article_list_ul.find_elements_by_tag_name('li')
for article in article_list_li:
title = article.find_element_by_tag_name('h3').text
writer = article.find_element_by_class_name('writer').text
link = article.find_element_by_tag_name('a').get_attribute('href')
print(title, writer, link)
pagination = driver.find_element_by_class_name('list-paging')
current_page = pagination.find_element_by_class_name('on').get_attribute('id')
next_page = str(int(current_page) + 1)
try:
next_page_btn = pagination.find_element_by_id(next_page)
next_page_btn.click()
except NoSuchElementException:
try:
next_btn = pagination.find_element_by_id('next')
next_btn.click()
except NoSuchElementException:
print('Scraping End.')
break
time.sleep(5)
위 코드에는 pagination 버튼을 찾아 수집 후 다음 페이지로 넘어갈 수 있도록 코드가 추가되었습니다. sleep은 서버에 부하가 가지 않도록 적절히 조절하면 되며, implicitly_wait과 같이 페이지 로딩 완료 후 정확하게 읽고싶은 경우에는 WebDriverWait 사용 방법을 찾아서 적용하면 됩니다.
여기까지 Selenium을 사용해서 데이터 스크래핑하는 방법에 대해 알아보았습니다. 전체적으로 보면 알 수 있듯이 사람이 웹 페이지에 직접 들어가서 하는 과정(이벤트)을 동일하게 진행한다고 생각하면 됩니다. 이 때문에 페이지 로딩을 기다려야하고 관련된 예외처리 등의 복잡한 과정이 반드시 필요합니다. CSR 방식을 사용할 경우 어쩔 수 없이 Selenium을 사용하게 되지만, Selenium을 사용하지 않고 데이터를 수집하는 방법도 있습니다. 다음에는 방법 중 하나인 API 추출에 대해 이야기하겠습니다.
댓글남기기