
Elasticsearch analyzer 후 다시 적용하기
Kibana에서 tag cloud로 시각화를 진행할 때 nori와 같은 analyzer를 많이 이용합니다. 실사용 하다보면 tokenizing되지 말아야할 단어가 생기거나 불필요한 단어가 생기게 됩니다. 아래 시각화 예시를 보면, 최근, 코로나와 같은 단어는 매 번 자주 등장하는 단어라 큰 의미가 없습니다. (한 글자 단어나 거리와 같이 사전 구축이 필요한 단어도 많지만, 여기서는 analyzer 업데이트 과정이 중요하기 때문에 넘어갑니다..)
 < Kibana tag cloud 시각화 >
< Kibana tag cloud 시각화 >
위 시각화를 개선하기 위해 아래 단계로 analyzer 수정 작업을 진행합니다.
- 사용중인 index close
- index analyzer 수정 (별도의 파일로 관리할 경우 생략 가능)
- index open
- 전체 document update by query 진행
1. index close
index의 analyzer를 수정하기 위해서는 우선 index를 close 합니다.
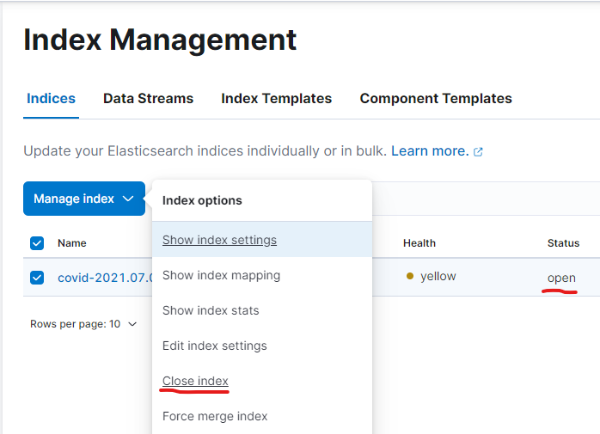
2. index analyzer 수정
index를 closed 상태로 만들고 stopwords를 추가합니다. 여기서는 편의상 리스트 형태로 추가했는데, 텍스트 파일로 관리하실 경우 텍스트에 이미 단어가 추가된 상태라면 생략이 가능합니다. (참고로 open/close 과정을 거쳐야 analyzer가 업데이트됩니다.)
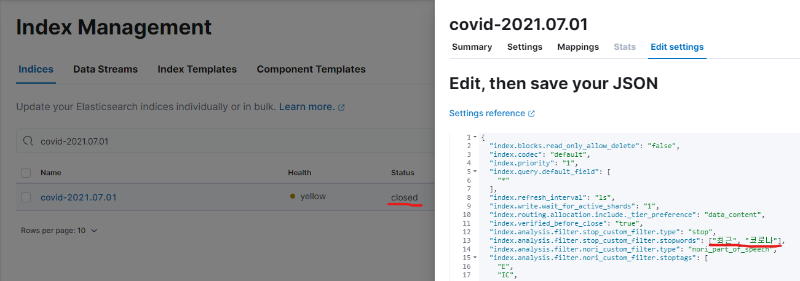
3. index open
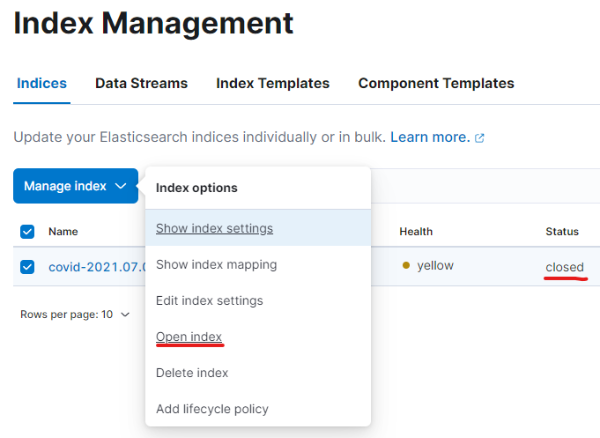
analyzer를 수정했으니 index를 다시 open합니다.
이제 다시 analyzer를 이용해보면 이제 최근과 코로나가 token으로 빠지지 않는 것을 확인할 수 있습니다.
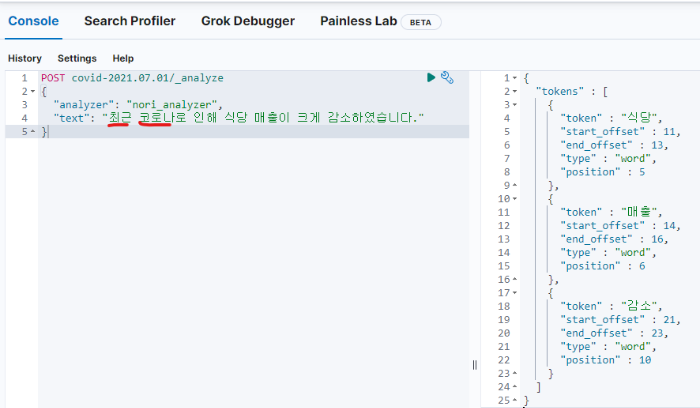
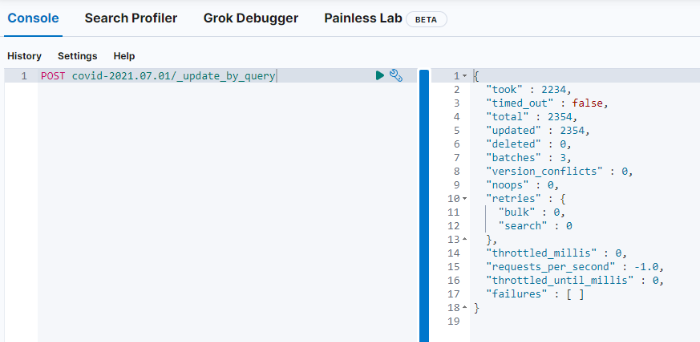
4. update by query
analyzer가 업데이트됐지만 시각화 결과는 바로 바뀌지 않습니다. 기존에 이미 생성된 document의 tokens는 업데이트되지 않기 때문입니다. 이를 update by query로 전체 document의 tokens를 업데이트할 수 있습니다.
index의 전체 ducment를 업데이트할 것이기 때문에 별도의 쿼리 없이 _update_by_query만 사용해서 전체 업데이트를 진행합니다. 제가 가지고있는 데이터 기준으로 2,354개를 업데이트하는데 2.2초(2,234ms)가 걸렸습니다.
이제 기존 시각화를 refresh 해보면 tokens가 업데이트되어 최근과 코로나가 빠진 tag cloud 시각화를 확인할 수 있습니다.

Reference
댓글남기기