
Windows에 ELK Stack 구축 2 (데이터 수집 및 적재)
이번엔 Logstash를 이용해서 Elasticsearch에 데이터를 적재해보겠습니다.
Logstash는 ELK Stack에서 사용되는 로그 수집기로, 실시간으로 데이터를 수집하기 위해 사용됩니다. 최근엔 Fluentd를 많이 사용하면서 EFK Stack을 구축하기도 합니다.
데이터 준비
이번 구축에는 공공데이터포털에서 제공하는 코로나 뉴스 빅데이터를 사용하겠습니다. 나중에 실제로 적용할때는 API나 Beat를 이용해서 실시간으로 수집하면 됩니다. 여기서는 편하게 csv파일로 받아서 사용하겠습니다. 제가 받은 데이터는 2021.07.01 ~ 2021.07.31 데이터입니다.
아래 있는 주기성 과거 데이터를 사용하면 더 많은 데이터로 해볼 수 있습니다. 받은 데이터는 한글 데이터를 읽기 위해 인코딩을 ANSI에서 UTF-8로 바꿔줍니다.
데이터는 일자, 언론사, 기고자, 제목, 본문 5가지만 사용하겠습니다.
수집 방법
먼저 logstash 폴더에 ‘conf.d’ 폴더를 만들어서 데이터를 넣을 ‘covid-csv.conf’ 파일을 만듭니다. 그리고 아래 내용을 작성합니다.
input {
file {
path => ["C:/covid_news/*.csv"]
start_position => "beginning"
}
}
filter {
csv {
skip_header => true
}
date {
match => ["column2", "YYYY-MM-dd"]
timezone => "UTC"
target => "@timestamp"
}
mutate { rename => ["column3", "press"] }
mutate { rename => ["column4", "contributor"] }
mutate { rename => ["column5", "title"] }
mutate { rename => ["column17", "content"] }
mutate { remove_field => ["message"] }
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "covid-%{+YYYY.MM.dd}"
}
stdout {}
}
위 코드에서 설명이 필요할 것 같은 부분 몇가지만 설명하겠습니다.
- filter를 통해 csv 포맷의 데이터를 추출합니다.
- date는 elasticsearch의 @timestamp에 데이터의 일자를 넣어주는데, 이때 timezone을 반드시 “UTC”로 맞춰줍니다.
- column 이름은 csv header 첫번째 컬럼부터 column1로 시작합니다. autodetect_column_names 옵션으로 컬럼 이름에 맞춰 자동으로 생성 후 매칭할 수도 있지만, 옵션이 잘 적용되지 않아 column 번호를 그냥 사용했습니다.
- rename으로 elasticsearch에서 사용될 column 이름으로 변환합니다.
- output의 index는 elasticsearch에서 생성되는 index 이름 포맷으로, 일반적으로 하나의 index에 데이터를 전부 저장하지 않고 날짜를 기준으로 나눠 저장합니다. 날짜는 @timestamp 기준입니다.
logstash를 이용해서 데이터를 적재하면 elasticsearch에서 index를 미리 생성하지 않아도 자동으로 생성됩니다.
이제 Kibana에서 Elasticsearch에 데이터가 잘 적재되었는지 index랑 데이터를 각각 확인해보겠습니다. index는 Management > Stack Management > Data > Index Management로 들어가서 covid로 검색해 날짜별로 생성됐는지 확인합니다.
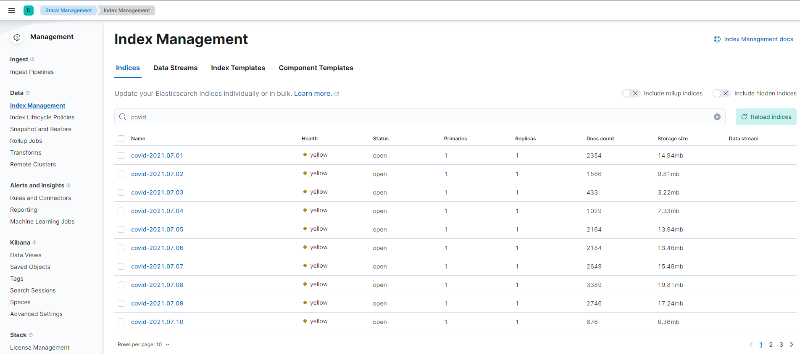 < index 적재 확인 >
< index 적재 확인 >
이제 데이터를 확인해보겠습니다. 데이터를 확인하기 위해서는 우선 패턴을 생성해줘야합니다. Management > Stack Management > Kibana > Data Views로 들어가서 Create data view 버튼을 누르고 “covid-*“로 패턴을 생성해줍니다.
참고로 기존의 “index pattern”이 kibana의 버전 업데이트 이후 “data view”로 변경되었습니다.
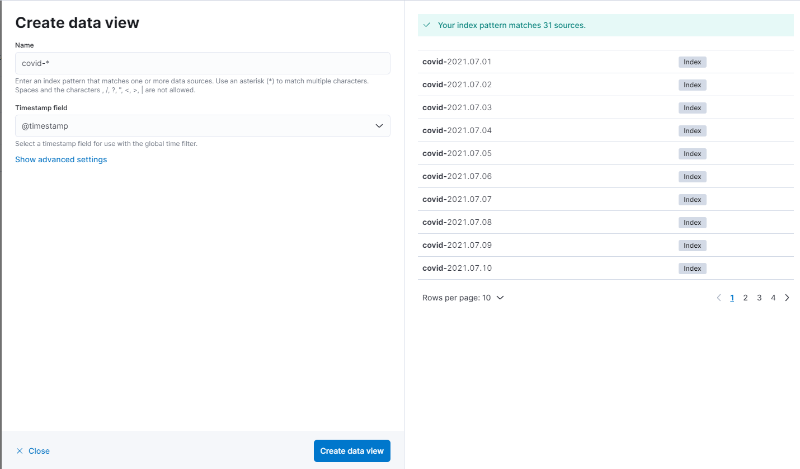 < data view 생성 >
< data view 생성 >
이제 적재된 데이터를 확인하기 위해 Analytics > Discover로 들어갑니다. 첫번째로 날짜를 적재한 데이터 구간으로 변경해주고 좌측 컬럼에 contributor, press, title, content를 추가(마우스 hover하면 뜨는 + 클릭)해서 깔끔하게 시각화해서 확인합니다.
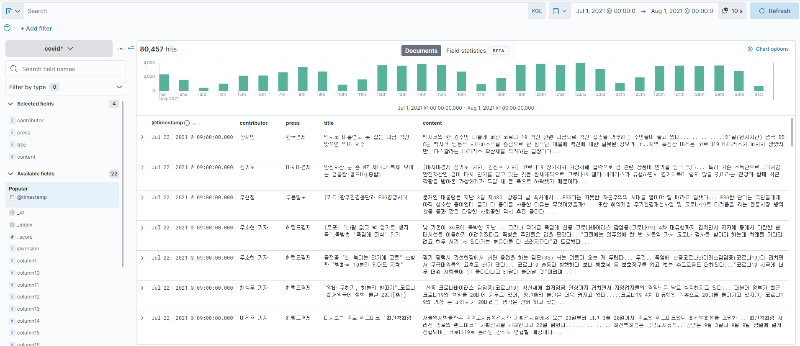 < 적재 데이터 확인 (Kibana discover) >
< 적재 데이터 확인 (Kibana discover) >
여기까지 logstash를 이용해서 elasticsearch에 데이터를 적재하고 kibana에서 확인하는 과정까지 진행했습니다. 다음엔 kibana dashboard에 시각화해서 확인해보도록 하겠습니다.
댓글남기기