
Windows에 ELK Stack 구축 4 (형태소 분석, Word Cloud)
ELK Stack 마지막 구축 과정으로 Word Cloud 시각화를 진행해보겠습니다. 데이터로 사용한 기사의 내용에서 사용된 단어의 빈도로 시각화하기 위해서는 전부 단어로 tokenizing 해야합니다. 이를 위해 형태소 분석기 플러그인을 사용해야합니다.
형태소 분석 (nori analyzer)
Elasticsearch는 analyzer를 이용해서 text와 함께 tokenizing된 데이터를 함께 저장할 수 있습니다. 기본적으로는 공백 기준으로 tokenizing이 가능하지만, 한국어의 경우 “을/를”과 같은 조사를 전부 지우고 사용해야하기 때문에 별도의 형태소 분석기를 사용해야합니다. Elasticsearch에서는 한국어 형태소 분석기로 nori analyzer를 plugin으로 지원합니다. 설치도 아래 한 줄만 실행하면 됩니다. (Elasticsearch를 끈 상태에서 설치 후 실행해줍니다)
bin\elasticsearch-plugin install analysis-nori
이제 index를 생성할 때 analyzer가 적용되도록 해야하는데, 그 전에 기존에 생성된 mappings 정보를 복사해옵니다. Stack Management > Index Management에서 만든 covid-* index 하나를 선택해서 Mappings에 있는 값을 복사합니다.
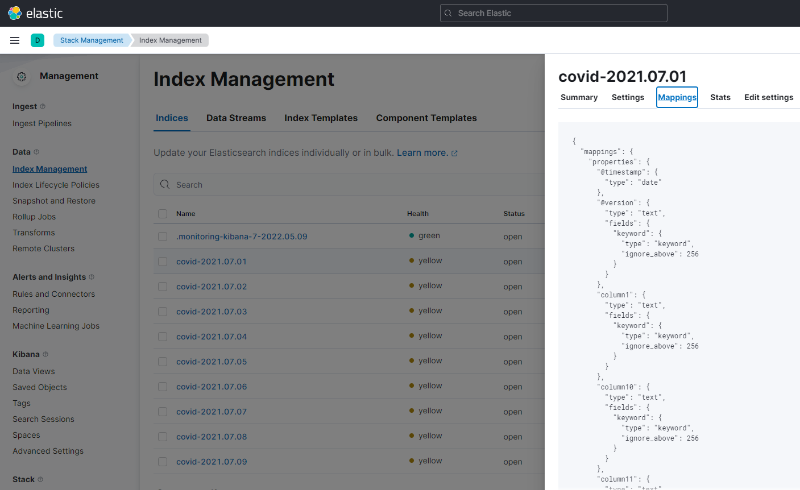
이 상태에서 analyzer 설정을 이어서 작성해보겠습니다. 작성한 설정을 elasticsearch에 conf.d 폴더를 생성해서 json 파일로 저장해놓겠습니다. 만들어진 파일 내용은 아래와 같습니다.
{
"mappings": {
"properties": {
"@timestamp": {
"type": "date"
},
"@version": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
...
"content": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
},
"nori": {
"type": "text",
"analyzer": "nori_analyzer",
"fielddata": true
}
}
},
"contributor": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"event": {
"properties": {
"original": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"host": {
"properties": {
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"log": {
"properties": {
"file": {
"properties": {
"path": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
},
"press": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"settings": {
"index": {
"analysis": {
"analyzer": {
"nori_analyzer": {
"type": "custom",
"tokenizer": "nori_tokenizer",
"filter": [
"nori_custom_filter",
"lowercase",
"stop_custom_filter"
]
}
},
"filter": {
"nori_custom_filter": {
"type": "nori_part_of_speech",
"stoptags": [
"E", "IC", "J", "MAG", "MAJ", "MM", "NA",
"NNB", "NNBC", "NP", "NR", "SC", "SE", "SF",
"SN", "SP", "SSC", "SSO", "SY",
"UNA", "UNKNOWN", "VA", "VCN", "VCP", "VV",
"VSV", "VX", "XPN", "XR", "XSA", "XSN", "XSV"
]
},
"stop_custom_filter": {
"type": "stop",
"stopwords": ["코로나"]
}
}
}
}
}
}
위 코드에서 중요한 부분은 “mappings”에서 “content”와 아래 “settings” > “index” > “analyzer” 입니다.
우선 mappings에서 content의 field에 tokenizing된 데이터를 저장하기 위해 “nori”라는 field를 추가하고, type으로 사용할 analyzer의 이름(nori_analyzer)과 “fielddata”: true를 입력합니다.
그리고 settings에 analyzer 설정을 위와 같이 추가하면 됩니다. 이 부분을 간단하게 설명하면 tokenizer에 nori_tokenizer를 입력해서 nori_analyzer를 만든 것이고, 3가지 필터를 추가한 것입니다. 필터는 순서대로 nori_custom_filter는 형태소의 품사를 임의로 지정해서 필터링하는 필터입니다(https://prohannah.tistory.com/73, Elasticsearch 노리(Nori)형태소 분석기의 stoptags 한글 품사 태그 정리 참조). 여기서는 명사빼고 모두 제외했다고 보면 됩니다.
lowercase는 대소문자 구분 없이 단어를 카운팅할 수 있도록 전부 소문자로 바꿔서 처리하기 위한 필터이고, stop_custom_filter는 이 외에 필터링이 필요한 단어를 직접 넣을 수 있습니다. 예를 들어 여기서는 “코로나”와 같이 단어가 불필요하게 많이 발생할 경우를 대비하여 미리 필터링할 수 있습니다.
이제 위 설정 파일 가지고 index를 생성하면 analyzer를 사용할 수 있지만, 우리는 index를 날짜별로 생성했기 때문에 하나 하나 설정하는 것은 무리가 있습니다. 이를 간단하게 해결하기 위해 kibana에서 index template을 만들겠습니다. Stack Management > Index Management에서 Index Templates 탭을 누르고 Create template를 누릅니다. Logistics에는 아래와 같이 template의 이름과 index patterns를 입력하고 넘어갑니다.
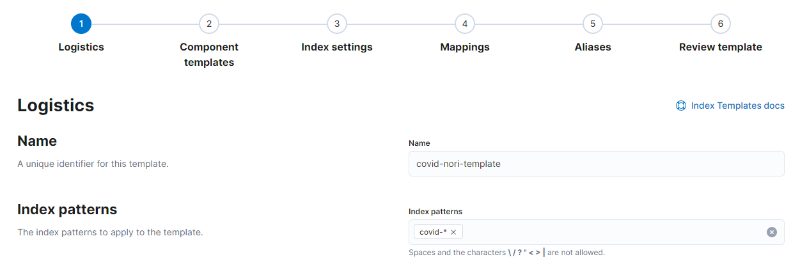 < Index template의 Logistics 설정 >
< Index template의 Logistics 설정 >
그리고 Index settings로 넘어가 아래와 같이 위 설정 파일의 “settings” > “index” 부분을 붙여넣습니다.
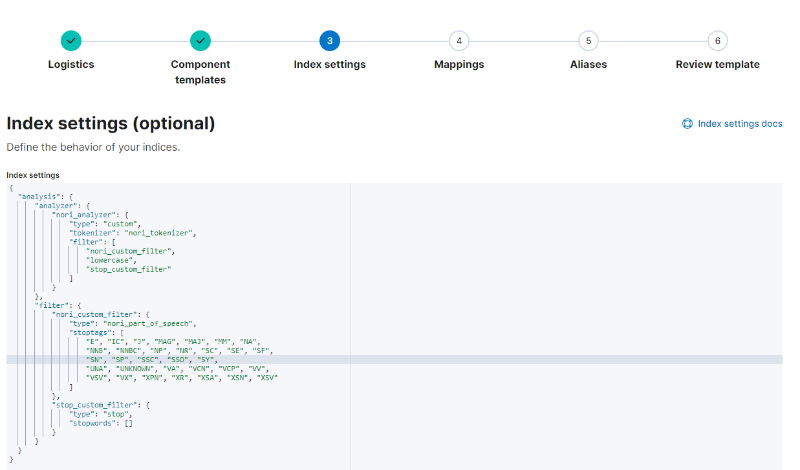 < Index template의 index 설정 >
< Index template의 index 설정 >
그 다음 Mappings로 넘어가 Load JSON 버튼을 누르고 설정 파일의 “mappings” 부분을 붙여넣습니다. 그러면 자동으로 아래와 같이 mappings 정보가 입력됩니다.
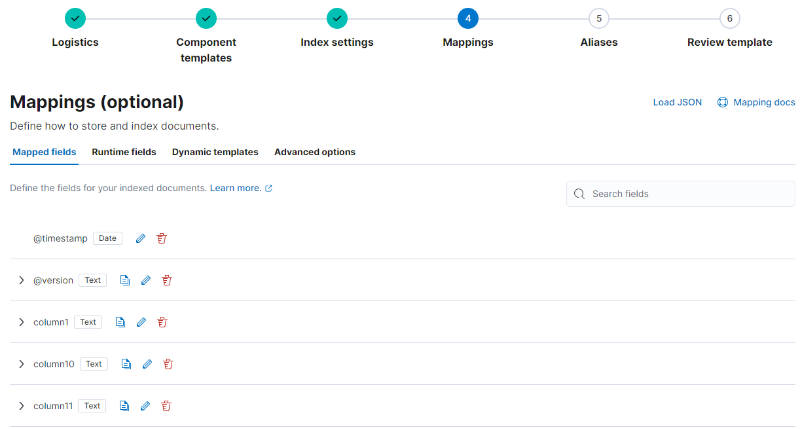 < Index template의 mappings 설정 >
< Index template의 mappings 설정 >
이제 마지막으로 넘어가 저장을 누르면 만든 nori-covid-template이 생성된 것을 볼 수 있습니다. 이제 기존에 만들어진 covid-* index를 모두 지우고 이전에 사용했던 방식과 같이 logstash를 이용해 데이터를 다시 넣습니다. Index 삭제는 Stack Management > Index Management에서 covid로 검색해서 나오는 index를 모두 삭제하면 편합니다.
데이터가 모두 적재됐으면 기존에 만들어두었던 Dashboard에 들어가서 Edit를 누릅니다. 그리고 Word Cloud를 만들기 위해 Select type을 누르고 Aggregation based에서 “Tag cloud”를 누릅니다. index는 당연히 covid-* 입니다.
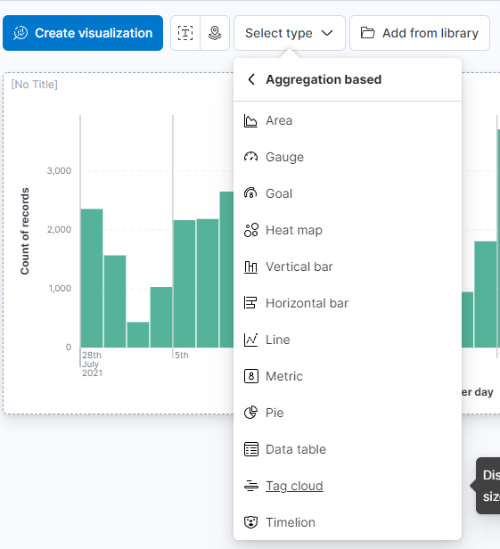
이제 Tag cloud 설정 화면에서 우측 Buckets에 Add를 눌러 Tags를 추가하고 Aggregation으로 Terms를 선택합니다. 그리고 Field는 “content.nori”를 선택하고 size를 크게 100을 입력한 뒤 Update를 누르면 아래와 같이 나오는 것을 볼 수 있습니다.
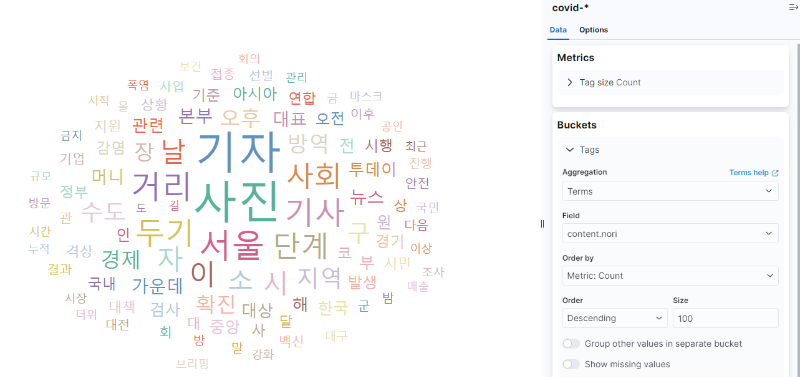 < Tag cloud 설정 화면 >
< Tag cloud 설정 화면 >
stop_custom_filter에 “코로나”를 추가했기 때문에 “코로나”라는 단어가 가운데 크게 나오지 않은 것을 볼 수 있습니다. 이제 위에 Save and return을 누르면 Word Cloud 시각화가 추가된 것을 볼 수 있습니다.
여기까지 간단한 Kibana 활용을 살펴봤습니다. Word Cloud는 트랜드 분석에서 많이 사용되니 잘 알아둬서 나중에 활용할 수 있었으면 좋겠습니다.
댓글남기기