
Google Cloud를 이용한 데이터 수집 파이프라인 구축기
Google Cloud를 이용해서 데이터 수집 파이프라인을 구축해본 과정을 정리해봤습니다. 클라우드를 사용하지만 초기 비용은 100원도 안나오는 걸로 확인했기 때문에 비용 걱정 없이 따라해보셔도 좋을 것 같습니다.
1. 아키텍처
전체적인 아키텍처는 다음과 같습니다.
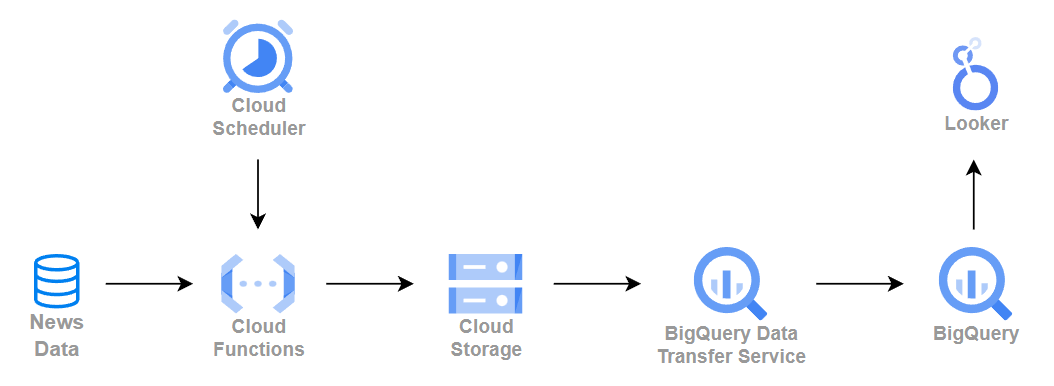 전체 아키텍처
전체 아키텍처
Cloud Scheduler를 통해 주기적으로 Cloud Functions을 실행시켜줍니다. Cloud Functions은 데이터를 수집해서 Cloud Storage(GCS)에 저장합니다. Cloud Storage에 저장된 데이터는 BigQuery의 Data Transfer Service(DTS)를 통해 주기적으로 BigQuery에 적재되고, 마지막으로 Looker Studio에서 간단하게 시각화해서 수집된 데이터를 그래프로 확인합니다.
2. 과정
2.1 뉴스 데이터 수집
뉴스 데이터 수집은 네이버의 뉴스 검색 API를 사용했습니다. (https://developers.naver.com/docs/serviceapi/search/news/news.md)
네이버 뉴스 검색 API는 뉴스 데이터를 쉽게 가져올 수 있다는 장점이 있지만, 본문을 일부밖에 못가져온다는 단점이 있습니다. 하지만 뉴스 본문을 꼭 전부 가져와야하는게 목적이 아니었기 때문에 네이버 뉴스 검색 API를 사용했습니다.
네이버 뉴스 검색 API를 사용하기 위해서는 아래와 같은 애플리케이션 등록 절차만 진행하면 됩니다. 방법은 Naver Developers에 Application(https://developers.naver.com/apps)으로 들어가서 애플리케이션 등록에서 진행할 수 있습니다.
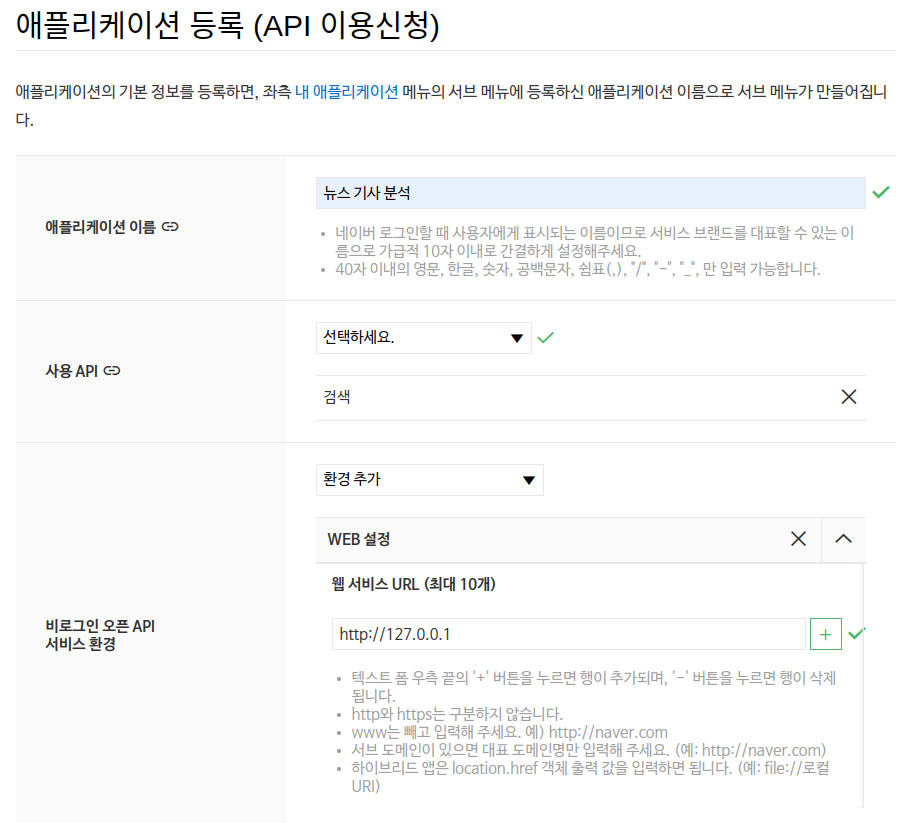 네이버 뉴스 검색 API 애플리케이션 등록
네이버 뉴스 검색 API 애플리케이션 등록
등록이 완료됐으면 생성한 애플리케이션에 들어가 Client ID와 Client Secret 정보를 확인해서 잘 기억해둡니다. 이 정보를 Cloud Functions에서 사용할 Container의 환경변수로 등록할 것 입니다.
2.2 Google Cloud 초기 셋팅
Google Cloud을 사용하기 위해서는 초기 세팅 작업이 필요한데, 순서는 1) 프로젝트 생성 -> 2) 결제 연동 -> 3) sdk 설치 입니다. 프로젝트 생성과 결제 연동은 쉽기 때문에 넘어가고, sdk 설치 과정은 아래 스크립트를 따라하면 됩니다. 여기서 혹시 region을 선택하는 과정이 뜬다면 asia-northeast3을 선택하면 됩니다.
$ echo "deb [signed-by=/usr/share/keyrings/cloud.google.gpg] https://packages.cloud.google.com/apt cloud-sdk main" | sudo tee -a /etc/apt/sources.list.d/google-cloud-sdk.list
$ curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key --keyring /usr/share/keyrings/cloud.google.gpg add -
$ sudo apt-get update && sudo apt-get install google-cloud-sdk
$ gcloud init
(구글 계정 로그인)
(프로젝트 선택)
N
혹시 여기서 나중에 이어서 진행할 때 인증 관련 오류가 발생한다면 gcloud auth login을 통해서 재인증을 하면 정상 동작합니다.
이후 진행되는 각각의 기능은 하나씩 Google Cloud Console에서 들어가 미리 사용등록을 해주는게 좋습니다.
2.3 Cloud Storage
수집한 데이터는 모두 Cloud Storage에 저장할 것이기 때문에 미리 생성 후 Bucket을 등록해줍니다. 데이터 위치만 단일 Region에서 asia-northeast3 (서울)을 선택하고 나머지는 기본값을 사용하면 됩니다.
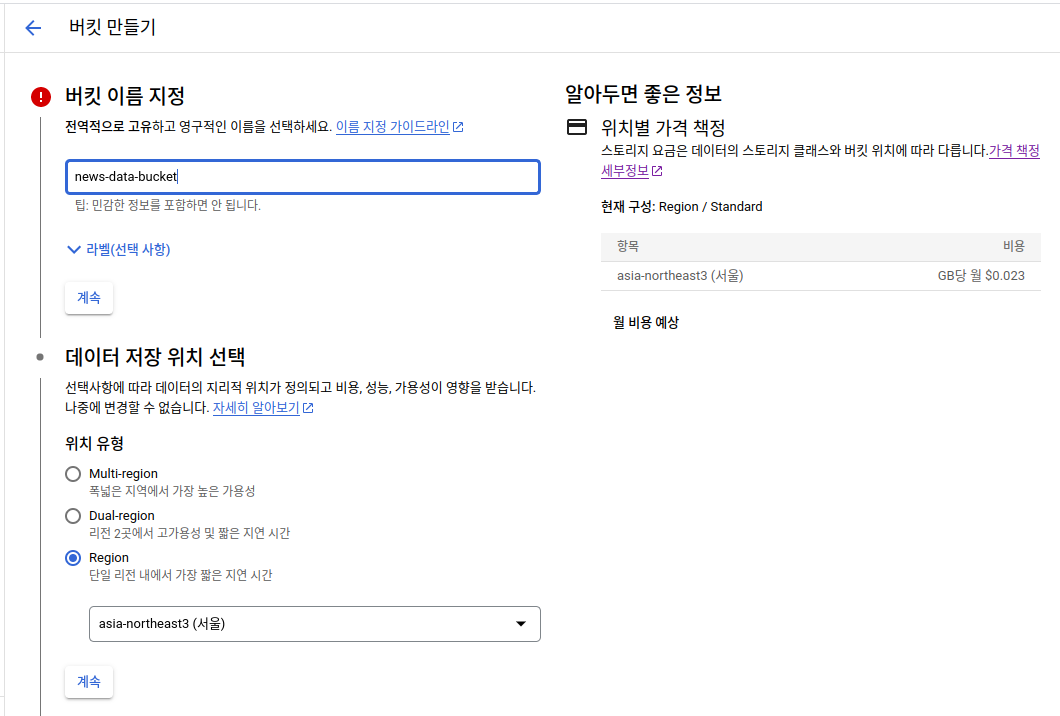 Cloud Storage Bucket 생성
Cloud Storage Bucket 생성
GB당 월 $0.023의 비용이 발생한다고 나와있지만 여기서는 이따 생성할 약 300MB의 Container만 사용하고 1MB 이하의 데이터만 생성됐다가 삭제하기 때문에 비용이 거의 안나온다고 생각하면 됩니다. (https://cloud.google.com/storage/pricing?hl=ko#asia)
2.4 Cloud Functions
Cloud Functions은 AWS의 Lambda와 동일한 동작을 합니다. python 파일과 requirements 파일만 가지고 등록하면 Cloud에서 빌드 과정을 거쳐 실행 가능한 컨테이너를 생성해줍니다.
등록에 필요한 내용은 GitHub(https://github.com/hyojupark/news_title_scrapper)에 올려놨으니 참고하시면 됩니다. 중요한 파일은 main.py, requirements.txt, env.yaml 3개 입니다.
├── README.md
├── credentials
│ ├── env.yaml
├── deploy.sh
├── main.py
└── requirements.txt
1 directory, 5 files
credentials에 있는 파일들은 깃에 올라가지 않도록 주의하도록 합니다. credentials/env.yaml에는 bucket 접근에 필요한 정보와 네이버 뉴스 검색 API 정보를 포함시켜줍니다.
PROJECT.ID: "toy-proejct"
BUCKET.NAME: "news-data-bucket"
NAVER_SEARCH_API.ID: "***"
NAVER_SEARCH_API.SECRET: "***"
수집하기 위한 파이썬 코드는 아래와 같습니다.
from datetime import datetime, timedelta
import os
import requests
import re
import json
import io
from google.cloud import storage
from google.oauth2 import service_account
import pandas as pd
from fastavro import writer, parse_schema
def clean_html(raw_html: str) -> str:
cleanr = re.compile('<.*?>|&([a-z0-9]+|#[0-9]{1,6}|#x[0-9a-f]{1,6});')
clean_text = re.sub(cleanr, '', raw_html)
return clean_text
def get_news_data():
naver_api_credentials = {
'id': os.environ['NAVER_SEARCH_API.ID'],
'secret': os.environ['NAVER_SEARCH_API.SECRET']
}
headers = {
'X-Naver-Client-Id': naver_api_credentials['id'],
'X-Naver-Client-Secret': naver_api_credentials['secret']
}
params = {
'query': '기자',
'display': 100,
'start': 1,
'sort': 'date'
}
return requests.get('https://openapi.naver.com/v1/search/news.json', headers=headers, params=params).json()
def news_data_save_to_gcs(request):
end_date = datetime.now().replace(second=0, microsecond=0)
start_date = end_date - timedelta(minutes=1)
schema = {
'doc': 'news_data',
'name': 'news_data',
'namespace': 'news_data',
'type': 'record',
'fields': [
{'name': 'title', 'type': 'string'},
{'name': 'description', 'type': 'string'},
{'name': 'originallink', 'type': 'string'},
{'name': 'link', 'type': 'string'},
{'name': 'pubDate', 'type': {'type': 'long', 'logicalType': 'timestamp-millis'}}
]
}
parsed_schema = parse_schema(schema)
resp = get_news_data()
df = pd.DataFrame(resp['items'])
df['title'] = df['title'].apply(lambda x: clean_html(x))
df['description'] = df['description'].apply(lambda x: clean_html(x))
df['pubDate'] = df['pubDate'].apply(lambda x: datetime.strptime(x, "%a, %d %b %Y %H:%M:%S %z").timestamp() * 1000)
filtered_df = df.loc[(df['pubDate'] >= start_date.timestamp() * 1000)
& (df['pubDate'] < end_date.timestamp() * 1000)]
if not filtered_df.empty:
client = storage.Client(project=os.environ['PROJECT.ID'])
bucket = client.get_bucket(os.environ['BUCKET.NAME'])
bytesio = io.BytesIO()
writer(bytesio, parsed_schema, filtered_df.to_dict('records'))
start_date_str = start_date.strftime('%Y%m%d%H%M%S')
end_date_str = end_date.strftime('%Y%m%d%H%M%S')
bucket.blob(f'raw_data/{start_date_str}_{end_date_str}.avro').upload_from_file(bytesio, rewind=True)
return {'status': 'success'}
코드는 직전 1분 내 등록된 뉴스를 가져와서 Avro 포맷으로 Cloud Storage에 등록하는 내용입니다. 네이버 뉴스 검색 API에 검색 키워드가 반드시 필요하기 때문에 기자를 키워드로 등록해서 검색에 사용했고, BigQuery에 쉽게 넣을 수 있는 Avro 포맷으로 데이터를 변환해서 저장했습니다.
이제 Cloud Functions에 배포하면 됩니다. 배포 스크립트는 deploy.sh에 넣어놨습니다.
gcloud functions deploy news_data_save_to_gcs --runtime python38 --trigger-http --env-vars-file=credentials/env.yaml
배포할 때는 python 코드 내에 실행시킬 함수 하나를 지정(news_data_save_to_gcs)하고, runtime(python 3.8) trigger(http), env-vars-file(환경변수 파일)을 옵션으로 추가합니다. 여기서 trigger는 뒤에서 설명할 Cloud Scheduler에서 trigger 용도로 사용됩니다.
배포 과정을 설명드리면 빌드 과정을 통해 Cloud Storage에 컨테이너 및 metadata가 저장되고 처음엔 1버전으로 등록됩니다. 배포할 때 마다 버전이 증가하면서 기존 컨테이너를 삭제하고 새로 추가합니다.
이제 배포하면 콘솔 웹에 아래와 같이 배포된 것을 확인할 수 있습니다.
 Cloud Functions Main
Cloud Functions Main
배포된 Cloud Functions에 들어가보면 호출 내용과 함께 등록된 소스, 변수(환경변수), 트리거, 로그와 테스트 탭을 확인할 수 있습니다. 각각의 탭을 들어가서 확인해보시고 테스트 탭에서 테스트를 진행해서 데이터가 정상적으로 가져와지는지 확인해는게 좋습니다. (위 코드는 1분 내 등록된 뉴스만 가져오기 때문에 테스트할 때는 시간을 늘려서 테스트해보는 것을 추천합니다.) 테스트했을 때 Cloud Storage의 bucket으로 들어가 생성된 파일이 있으면 정상 동작한 것입니다.
Cloud Functions 사용 비용은 호출건으로 봤을 때 월 200만건 무료이고 컴퓨팅 및 네트워크 비용이 별도로 발생하지만 이 부분도 거의 무료로 사용 가능한 수준이라고 보시면 될 것 같습니다. (https://cloud.google.com/functions/pricing?hl=ko)
2.5 Cloud Scheduler
배포한 Cloud Functions를 1분 단위로 실행하기 위해서 Cloud Scheduler에 등록해줍니다. 등록은 Cloud Scheduler에 들어가서 작업 만들기 버튼을 눌러서 UI 상에서 진행합니다.
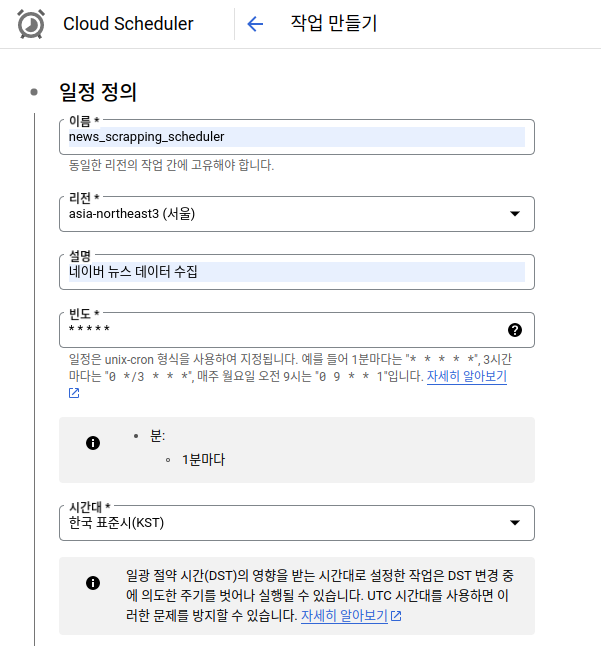 Cloud Scheduler 설정 1
Cloud Scheduler 설정 1
위 설정에서 빈도가 cron 형식을 사용합니다. 필요에 따라서 변경해서 사용하시면 됩니다.
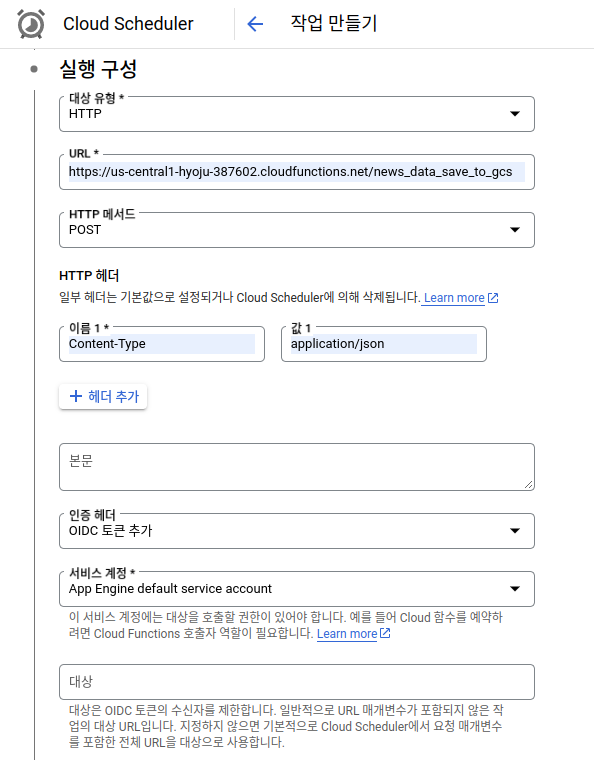 Cloud Scheduler 설정 2
Cloud Scheduler 설정 2
여기서 HTTP로 설정하고 Cloud Functions의 트리거 URL을 가져와서 입력해줍니다. 그리고 header에 Content-Type: application/json를 추가(생략 가능)합니다. 마지막으로 인증 헤더에서 OIDC 토큰 추가를 선택하고 서비스 계정에서 사용중인 계정을 선택합니다. 나머지 뒤의 설정은 그대로 두고 만들기를 눌러 생성해줍니다.
이제 Cloud Scheduler까지 정상적으로 생성된 것을 확인할 수 있습니다.
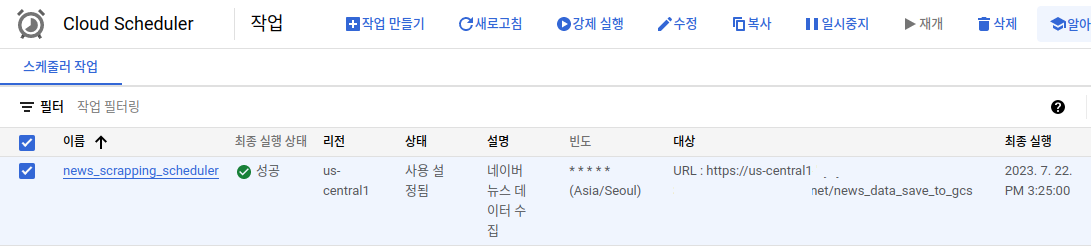 Cloud Scheduler Main
Cloud Scheduler Main
Cloud Scheduler는 3개까지 무료로 사용 가능합니다. (https://cloud.google.com/scheduler/pricing?hl=ko)
2.6 BigQuery
이제 BigQuery에 데이터를 저장하기 위한 테이블을 생성합니다. 생성 방법은 BigQuery 페이지에 들어가서 분석 > SQL 작업공간 > 탐색기 > 프로젝트 이름 오른족 : 버튼을 눌러 데이터 세트 만들기를 눌러줍니다. 생성할 때 위치 유형만 리전을 선택해서 asia-northeast3를 선택해서 생성해줍니다.
생성된 데이터 세트 이름 오른쪽 : 버튼을 눌러 테이블 만들기를 눌러줍니다. 테이블을 생성할때는 Cloud Functions에서 사용했던 python 코드 내 Avro 스키마가 사용될 수 있도록 아래와 같이 맞춰서 만들어줘야합니다.
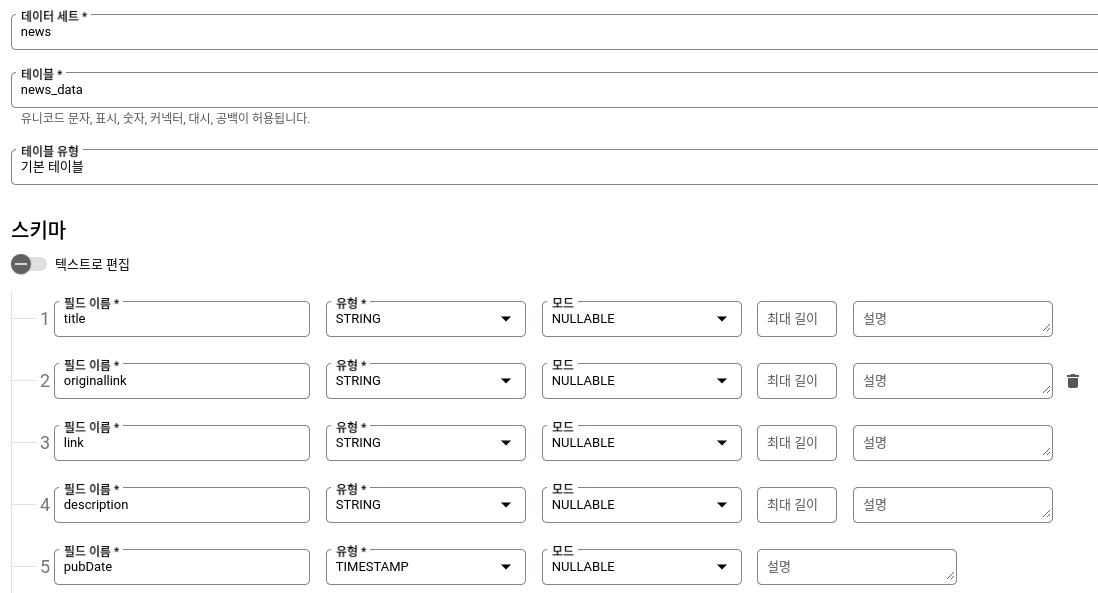 BigQuery Table Schema
BigQuery Table Schema
2.7 BigQuery Data Transfer Service
BigQuery는 Cloud Storage에 저장된 데이터 파일을 별도의 코드 작성없이 BigQuery에 넣을 수 있는 Data Transfer Service를 제공합니다. BigQuery 페이지에서 데이터 전송으로 들어가 만들면 생성 가능합니다.
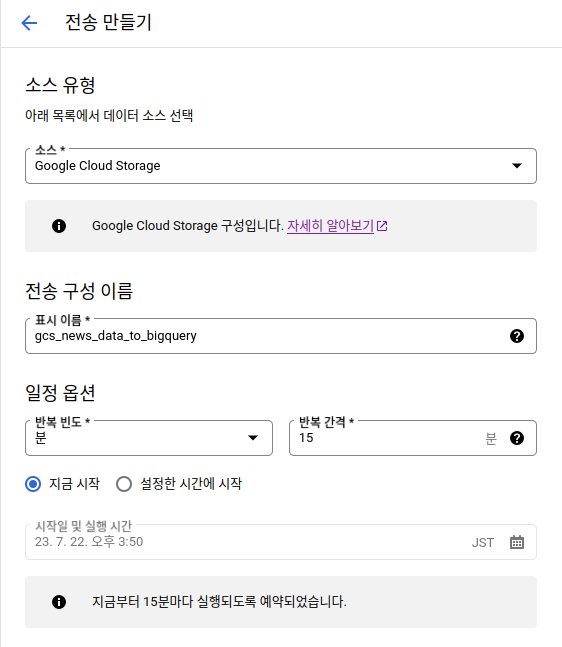 Data Transfer Service Setting 1
Data Transfer Service Setting 1
소스는 Google Cloud Storage를 선택하고 동작 주기를 설정합니다. 주기는 최소 15분 단위까지만 설정이 가능합니다.
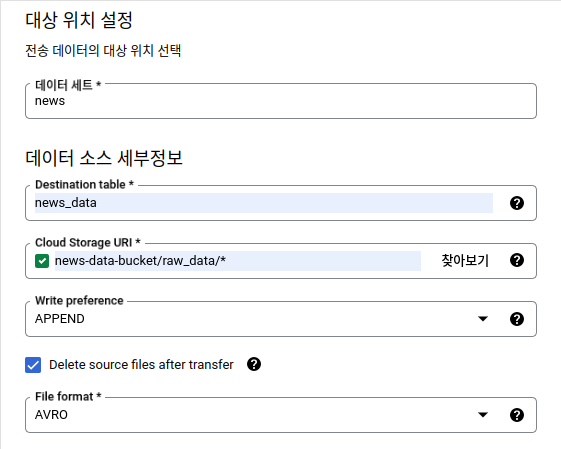 Data Transfer Service Setting 2
Data Transfer Service Setting 2
데이터 세트를 선택하고 Table 이름은 직접 입력해줍니다. 그리고 데이터가 저장되는 Cloud Storage URI를 입력해주는데, 디렉토리 내 저장된 파일을 모두 가져오도록 *을 꼭 붙여줍니다. 그리고 Delete source files after transfer를 체크헤줘서 전송된 파일은 삭제되도록 하고, 파일 포맷은 저장된 파일 포맷인 AVRO를 선택합니다.
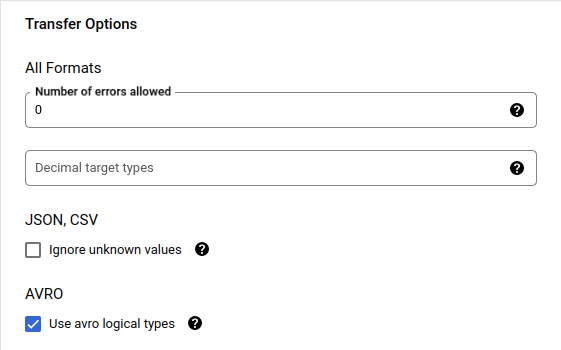 Data Transfer Service Setting 3
Data Transfer Service Setting 3
마지막으로 AVRO 설정 중 Use avro logical types를 체크해서 Avro 스키마에 설정에 있던 logical type이 잘 변환되도록 합니다.
생성된 Data Transfer Service에 들어가보면 정상 실행됐는지 확인해볼 수 있습니다.
BigQuery는 쿼리 시 발생하는 데이터 양에 따라 요금이 달라지기 때문에 계산하기 조금 번거롭지만, 월 1TB까지 무료로 사용이 가능하기 때문에 수집되는 뉴스 데이터 정도는 거의 무료 사용이 가능합니다.
2.8 Looker Studio
시각화는 BigQuery에서 쿼리를 작성하고 Looker Studio로 탐색을 하면 바로 시각화할 수 있습니다. 시각화에 사용한 쿼리는 아래와 같습니다. (project_id, dataset_id, table_id는 변경해서 사용하시면 됩니다.)
SELECT
TIMESTAMP_ADD(DATE_TRUNC(pubDate, HOUR), INTERVAL 9 HOUR) AS hour,
COUNT(*) AS count
FROM `{project_id}.{dataset_id}.{table_id}`
GROUP BY
hour
ORDER BY
hour
쿼리는 시간당 데이터 수를 모아서 보는 쿼리입니다. 저는 데이터를 미리 수집해놨기 때문에 아래와 같이 시간 당 수집된 데이터 수를 확인할 수 있습니다.
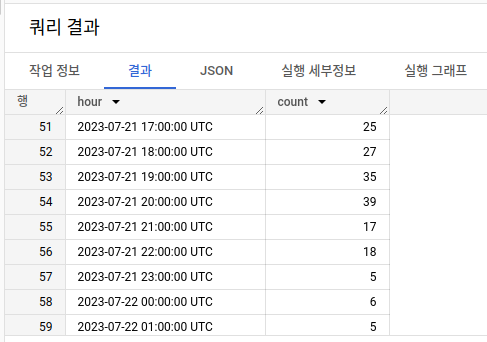 BigQuery 쿼리 실행 결과
BigQuery 쿼리 실행 결과
이제 우측에 데이터 탐색을 누르고 Looker Studio로 탐색을 눌러줍니다. 그러면 새 페이지에 테이블과 차트 하나가 생성돼있는데, 이상하게 생성된 차트는 삭제하고 차트 추가를 눌러 시계열 차트를 누르면 일단위로 생성된 데이터를 확인할 수 있습니다.
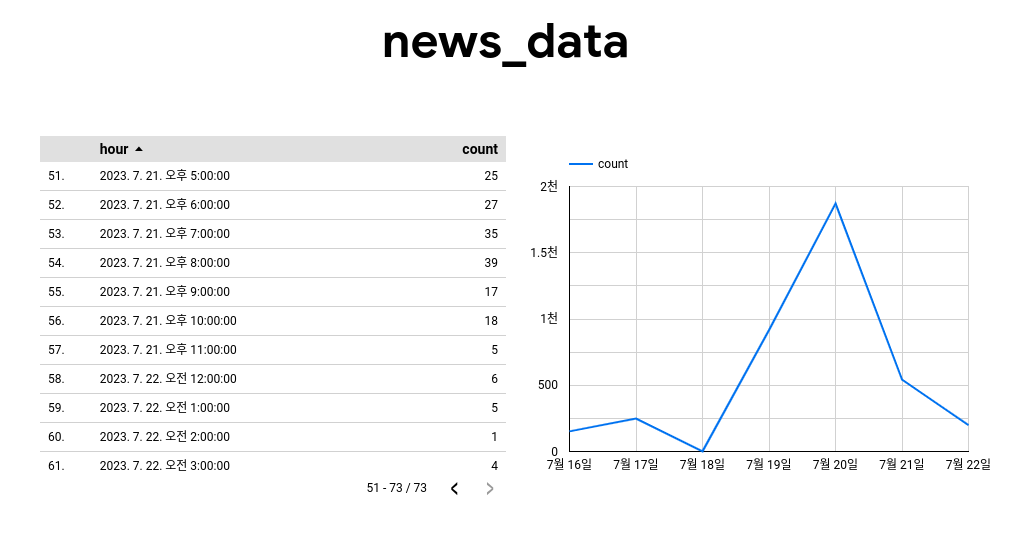 Looker Studio Reporting
Looker Studio Reporting
이제 우측 상단에 저장 및 공유 버튼을 눌러 만든 레포트를 저장하면 됩니다. 저장된 레포트는 Looker Studio에서 확인이 가능한데, Cloud Console에서 Looker Studio를 검색해서 들어가면 안나오고 https://lookerstudio.google.com/에 들어가서 확인하면 됩니다.
여기까지하면 전체 데이터 수집 파이프라인이 완성됩니다!
3. 결론
Cloud 경험을 해보기 위해 진행해봤는데, 생각보다 무료로 사용 가능한 부분이 많아서 스터디으로 해보기 굉장히 좋았었습니다. 이후에는 수집된 데이터로 해볼 수 있는 것들을 찾아서 조금 더 발전시켜볼 계획입니다.
댓글남기기