
MLflow PyTorch 학습 example (using MLproject, pip)
본 예제는 Anaconda 없이 pip requirements를 가지고 MLflow pytorch example을 진행하는 방법에 대해 작성하였습니다.
(pyenv dependency로 인해 윈도우에서는 진행이 불가능합니다.)
예제 코드(파일)
예제 코드는 https://github.com/mlflow/mlflow/tree/master/examples/pytorch/MNIST의 코드를 그대로 가져와서 MLproject와 .yaml만 수정해서 사용했습니다.
1. mnist_autolog_example.py
- 예제 코드 그대로 사용 (아래
코드 보기클릭)
코드 보기
#
# Trains an MNIST digit recognizer using PyTorch Lightning,
# and uses Mlflow to log metrics, params and artifacts
# NOTE: This example requires you to first install
# pytorch-lightning (using pip install pytorch-lightning)
# and mlflow (using pip install mlflow).
#
# pylint: disable=arguments-differ
# pylint: disable=unused-argument
# pylint: disable=abstract-method
import pytorch_lightning as pl
import mlflow.pytorch
import logging
import os
import torch
from argparse import ArgumentParser
from pytorch_lightning.callbacks.early_stopping import EarlyStopping
from pytorch_lightning.callbacks import ModelCheckpoint
from pytorch_lightning.callbacks import LearningRateMonitor
from torch.nn import functional as F
from torch.utils.data import DataLoader, random_split
from torchvision import datasets, transforms
try:
from torchmetrics.functional import accuracy
except ImportError:
from pytorch_lightning.metrics.functional import accuracy
class MNISTDataModule(pl.LightningDataModule):
def __init__(self, **kwargs):
"""
Initialization of inherited lightning data module
"""
super(MNISTDataModule, self).__init__()
self.df_train = None
self.df_val = None
self.df_test = None
self.train_data_loader = None
self.val_data_loader = None
self.test_data_loader = None
self.args = kwargs
# transforms for images
self.transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
)
def setup(self, stage=None):
"""
Downloads the data, parse it and split the data into train, test, validation data
:param stage: Stage - training or testing
"""
self.df_train = datasets.MNIST(
"dataset", download=True, train=True, transform=self.transform
)
self.df_train, self.df_val = random_split(self.df_train, [55000, 5000])
self.df_test = datasets.MNIST(
"dataset", download=True, train=False, transform=self.transform
)
def create_data_loader(self, df):
"""
Generic data loader function
:param df: Input tensor
:return: Returns the constructed dataloader
"""
return DataLoader(
df, batch_size=self.args["batch_size"], num_workers=self.args["num_workers"]
)
def train_dataloader(self):
"""
:return: output - Train data loader for the given input
"""
return self.create_data_loader(self.df_train)
def val_dataloader(self):
"""
:return: output - Validation data loader for the given input
"""
return self.create_data_loader(self.df_val)
def test_dataloader(self):
"""
:return: output - Test data loader for the given input
"""
return self.create_data_loader(self.df_test)
class LightningMNISTClassifier(pl.LightningModule):
def __init__(self, **kwargs):
"""
Initializes the network
"""
super(LightningMNISTClassifier, self).__init__()
# mnist images are (1, 28, 28) (channels, width, height)
self.optimizer = None
self.scheduler = None
self.layer_1 = torch.nn.Linear(28 * 28, 128)
self.layer_2 = torch.nn.Linear(128, 256)
self.layer_3 = torch.nn.Linear(256, 10)
self.args = kwargs
@staticmethod
def add_model_specific_args(parent_parser):
parser = ArgumentParser(parents=[parent_parser], add_help=False)
parser.add_argument(
"--batch_size",
type=int,
default=64,
metavar="N",
help="input batch size for training (default: 64)",
)
parser.add_argument(
"--num_workers",
type=int,
default=3,
metavar="N",
help="number of workers (default: 3)",
)
parser.add_argument(
"--lr",
type=float,
default=0.001,
metavar="LR",
help="learning rate (default: 0.001)",
)
return parser
def forward(self, x):
"""
:param x: Input data
:return: output - mnist digit label for the input image
"""
batch_size = x.size()[0]
# (b, 1, 28, 28) -> (b, 1*28*28)
x = x.view(batch_size, -1)
# layer 1 (b, 1*28*28) -> (b, 128)
x = self.layer_1(x)
x = torch.relu(x)
# layer 2 (b, 128) -> (b, 256)
x = self.layer_2(x)
x = torch.relu(x)
# layer 3 (b, 256) -> (b, 10)
x = self.layer_3(x)
# probability distribution over labels
x = torch.log_softmax(x, dim=1)
return x
def cross_entropy_loss(self, logits, labels):
"""
Initializes the loss function
:return: output - Initialized cross entropy loss function
"""
return F.nll_loss(logits, labels)
def training_step(self, train_batch, batch_idx):
"""
Training the data as batches and returns training loss on each batch
:param train_batch: Batch data
:param batch_idx: Batch indices
:return: output - Training loss
"""
x, y = train_batch
logits = self.forward(x)
loss = self.cross_entropy_loss(logits, y)
return {"loss": loss}
def validation_step(self, val_batch, batch_idx):
"""
Performs validation of data in batches
:param val_batch: Batch data
:param batch_idx: Batch indices
:return: output - valid step loss
"""
x, y = val_batch
logits = self.forward(x)
loss = self.cross_entropy_loss(logits, y)
return {"val_step_loss": loss}
def validation_epoch_end(self, outputs):
"""
Computes average validation accuracy
:param outputs: outputs after every epoch end
:return: output - average valid loss
"""
avg_loss = torch.stack([x["val_step_loss"] for x in outputs]).mean()
self.log("val_loss", avg_loss, sync_dist=True)
def test_step(self, test_batch, batch_idx):
"""
Performs test and computes the accuracy of the model
:param test_batch: Batch data
:param batch_idx: Batch indices
:return: output - Testing accuracy
"""
x, y = test_batch
output = self.forward(x)
_, y_hat = torch.max(output, dim=1)
test_acc = accuracy(y_hat.cpu(), y.cpu())
return {"test_acc": test_acc}
def test_epoch_end(self, outputs):
"""
Computes average test accuracy score
:param outputs: outputs after every epoch end
:return: output - average test loss
"""
avg_test_acc = torch.stack([x["test_acc"] for x in outputs]).mean()
self.log("avg_test_acc", avg_test_acc)
def configure_optimizers(self):
"""
Initializes the optimizer and learning rate scheduler
:return: output - Initialized optimizer and scheduler
"""
self.optimizer = torch.optim.Adam(self.parameters(), lr=self.args["lr"])
self.scheduler = {
"scheduler": torch.optim.lr_scheduler.ReduceLROnPlateau(
self.optimizer,
mode="min",
factor=0.2,
patience=2,
min_lr=1e-6,
verbose=True,
),
"monitor": "val_loss",
}
return [self.optimizer], [self.scheduler]
if __name__ == "__main__":
parser = ArgumentParser(description="PyTorch Autolog Mnist Example")
# Early stopping parameters
parser.add_argument(
"--es_monitor", type=str, default="val_loss", help="Early stopping monitor parameter"
)
parser.add_argument("--es_mode", type=str, default="min", help="Early stopping mode parameter")
parser.add_argument(
"--es_verbose", type=bool, default=True, help="Early stopping verbose parameter"
)
parser.add_argument(
"--es_patience", type=int, default=3, help="Early stopping patience parameter"
)
parser = pl.Trainer.add_argparse_args(parent_parser=parser)
parser = LightningMNISTClassifier.add_model_specific_args(parent_parser=parser)
args = parser.parse_args()
dict_args = vars(args)
if "strategy" in dict_args:
if dict_args["strategy"] == "None":
dict_args["strategy"] = None
model = LightningMNISTClassifier(**dict_args)
dm = MNISTDataModule(**dict_args)
dm.setup(stage="fit")
early_stopping = EarlyStopping(
monitor=dict_args["es_monitor"],
mode=dict_args["es_mode"],
verbose=dict_args["es_verbose"],
patience=dict_args["es_patience"],
)
checkpoint_callback = ModelCheckpoint(
dirpath=os.getcwd(), save_top_k=1, verbose=True, monitor="val_loss", mode="min"
)
lr_logger = LearningRateMonitor()
trainer = pl.Trainer.from_argparse_args(
args, callbacks=[lr_logger, early_stopping, checkpoint_callback], checkpoint_callback=True
)
# It is safe to use `mlflow.pytorch.autolog` in DDP training, as below condition invokes
# autolog with only rank 0 gpu.
# For CPU Training
if dict_args["gpus"] is None or int(dict_args["gpus"]) == 0:
mlflow.pytorch.autolog()
elif int(dict_args["gpus"]) >= 1 and trainer.global_rank == 0:
# In case of multi gpu training, the training script is invoked multiple times,
# The following condition is needed to avoid multiple copies of mlflow runs.
# When one or more gpus are used for training, it is enough to save
# the model and its parameters using rank 0 gpu.
mlflow.pytorch.autolog()
else:
# This condition is met only for multi-gpu training when the global rank is non zero.
# Since the parameters are already logged using global rank 0 gpu, it is safe to ignore
# this condition.
logging.info("Active run exists.. ")
trainer.fit(model, dm)
trainer.test(datamodule=dm)
2. MLproject
- MLproject의 env는 conda_env(conda)와 python_env(pip) 2개를 지원합니다. (https://www.mlflow.org/docs/latest/models.html#additional-logged-files)
- conda_env 부분을 python_env로 변경
name: mnist-autolog-example
python_env: python_env.yaml
entry_points:
main:
parameters:
max_epochs: {type: int, default: 5}
gpus: {type: int, default: 0}
strategy: {type str, default: "None"}
batch_size: {type: int, default: 64}
num_workers: {type: int, default: 3}
learning_rate: {type: float, default: 0.001}
patience: {type int, default: 3}
mode: {type str, default: 'min'}
verbose: {type bool, default: True}
monitor: {type str, default: 'val_loss'}
command: |
python mnist_autolog_example.py \
--max_epochs {max_epochs} \
--gpus {gpus} \
--strategy {strategy} \
--batch_size {batch_size} \
--num_workers {num_workers} \
--lr {learning_rate} \
--es_patience {patience} \
--es_mode {mode} \
--es_verbose {verbose} \
--es_monitor {monitor}
3. python_env.yaml
- python version과
pip,setuptools,wheel과같은 build dependencies version을 작성하고 나머지 packages version은requirements.txt에 작성합니다. - python version만 빼고 나머지(build dependencies, requirements)는 예제 코드와 동일한 version을 사용했습니다.
python: 3.7.5
build_dependencies:
- pip==21.1.3
- setuptools==57.4.0
- wheel==0.37.0
dependencies:
- -r requirements.txt
4. requirements.txt
mlflow>=1.17.0
torch==1.9.0
torchvision>=0.9.1
pytorch-lightning==1.6.1
protobuf<4.0.0
이렇게 mnist_autolog_example.py, MLproject, python_env.yaml, requirements.txt 4개의 예제 코드(파일)을 작성했습니다.
pyenv 설치
MLflow의 python_env를 사용하기 위해서는 pyenv를 설치해야합니다. 우선 pyenv 설치에 필요한 dependencies를 설치합니다.
$ sudo apt install git build-essential libreadline-dev zlib1g-dev libbz2-dev \
libsqlite3-dev libssl-dev liblzma-dev
그리고 pyenv를 git으로 설치합니다.
$ git clone https://github.com/pyenv/pyenv.git ~/.pyenv
pyenv를 환경변수에 추가합니다.
$ vi ~/.bashrc
# 맨 밑에 아래 코드 추가
export PYENV_ROOT="$HOME/.pyenv"
export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init -)"
그리고 터미널을 재실행합니다. (source ~/.bashrc를 해도 되지만 저는 virtualenv에서 pyenv 설정 적용이 안됐습니다..)
MLflow 프로젝트 실행
이제 작성한 코드를 실행하도록 하겠습니다. 작성한 코드가 있는 디렉토리에서 아래 명령어를 입력하면 바로 프로젝트(학습)가 시작됩니다.
pytorch_example$ mlflow run .
프로젝트는 가상환경에 1) python 설치, 2) build_dependencies 설치, 3) requirements 설치, 4) python 학습 코드 실행, 5) 결과 출력 순으로 진행되면서 아래와 같이 출력되면 성공적으로 진행된 것입니다.
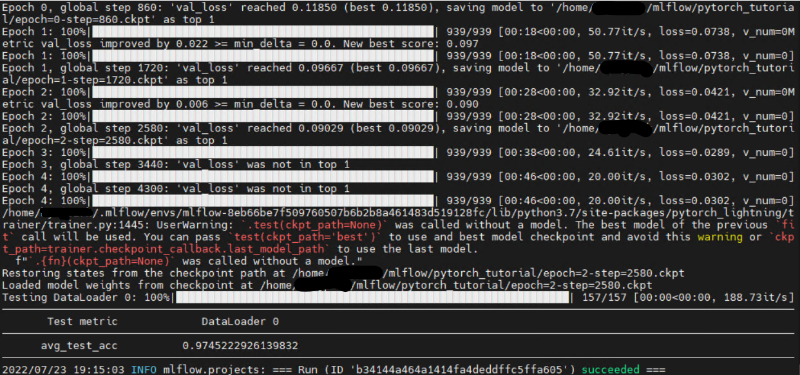 mlflow project 실행 결과
mlflow project 실행 결과
MLflow UI에 접속해보면 아래와 같이 Artifact가 정상적으로 생성된 것을 확인할 수 있습니다.
pytorch_example$ mlflow ui
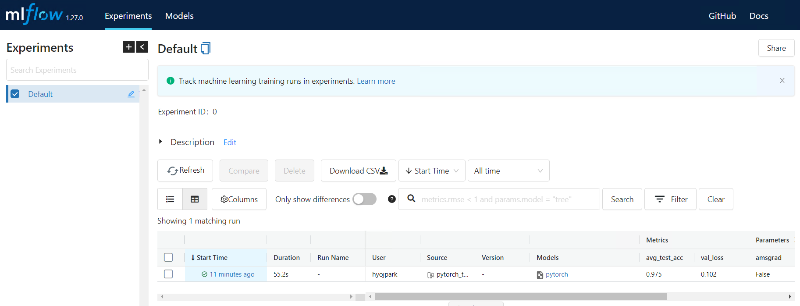 MLflow UI
MLflow UI
댓글남기기