
MLflow Tracking Server 연동 학습 예시
연관 포스트
설치 환경
설치 환경은 이전에 작성했던 글MLflow PyTorch 학습 example (using MLproject, pip)을 기반으로 진행하겠습니다. Helm으로 MLflow를 설치하고 PostgreSQL과 S3가 연동되어있는 상태입니다.
본 설치는 MLflow 설계 시나리오 5 기반으로 작성하였습니다.
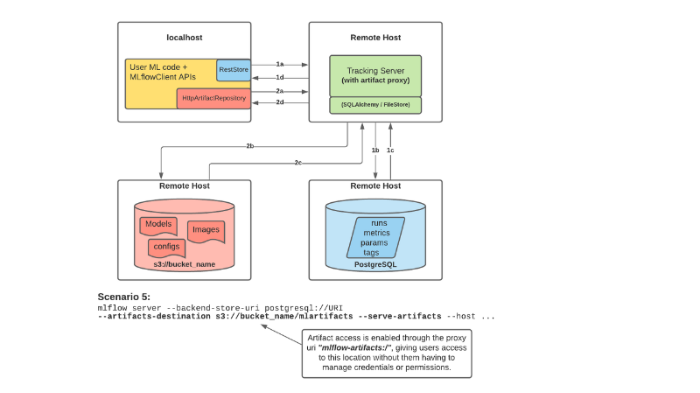 MLflow Scenario 5
MLflow Scenario 5
코드
# 예제 코드(파일)
예시 코드도 이전에 작성했던 위 글을 기반으로 진행하겠습니다. 위 글의 mnist_autolog_example.py, MLproject, python_env.yaml, requirements.txt 4개 파일을 가지고 시작합니다.
본 예제는 Anaconda 없이 pip requirements를 가지고 MLflow pytorch example을 진행하는 방법에 대해 작성하였습니다. (pyenv dependency로 인해 윈도우에서는 진행이 불가능합니다.)
설정해야할 부분은 다음과 같습니다.
- Artifact 저장 코드 추가
- 환경 변수 설정 (S3, MLflow)
1. Artifact 저장 코드 추가
위 예제 코드에서는 ModelCheckpoint의 저장 경로가 os.getcwd()로 되어있는데, 이 부분을 특정 폴더로 지정해줍니다. 여기서는 "output_model" 폴더에 저장하겠습니다.
...
checkpoint_callback = ModelCheckpoint(
dirpath="output_model", save_top_k=1, verbose=True, monitor="val_loss", mode="min"
)
...
그리고 코드 제일 마지막에 artifact 저장 코드를 추가합니다. 예제에서 test 코드 바로 밑에 추가하면 됩니다.
...
trainer.fit(model, dm)
trainer.test(datamodule=dm)
mlflow.log_artifacts('output_model')
2. 환경 변수 설정(S3, MLflow)
S3 접근은 Tracking Server에서 이루어지지만 인증 과정이 필요하기 때문에 관련 설정과 Tracking Server URI를 추가합니다.
$ export AWS_ACCESS_KEY_ID="..."
$ export AWS_SECRET_ACCESS_KEY="..."
$ export MLFLOW_S3_ENDPOINT_URL="https://..." # 별도 S3 서버 사용 시 지정
$ export MLFLOW_TRACKING_URI="https://..."
학습 및 결과 확인
학습은 기존과 동일하게 진행하면 됩니다.
$ mlflow run .
정상적으로 이루어졌다면 Tracking Server의 Experiments에 학습 이력과 모델이 추가된 것을 확인할 수 있습니다.
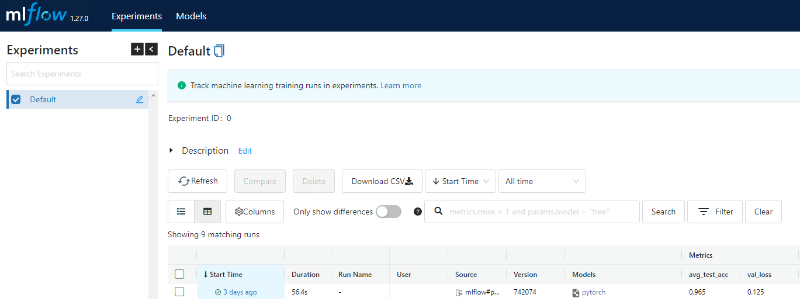
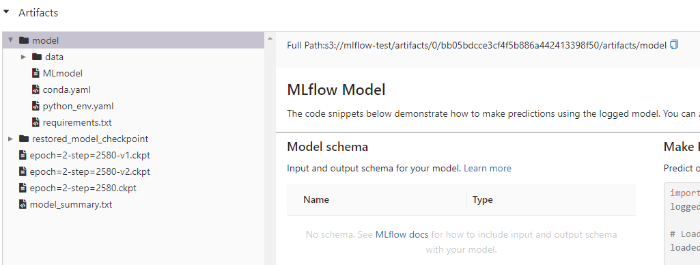
실험 내역에 들어갔을 때 Parameters, Metrics 등의 정보와 Artifacts가 s3에 저장되어있다고 잘 떠있으면 성공입니다.
댓글남기기