
피드백 루프 인프라 (Feedback Loop Infrastructure)
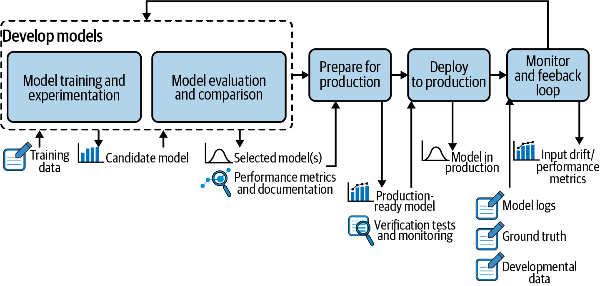 출처: Introducing MLOps - End-to-end ML process를 위한 CD(Continuous Delivery)
출처: Introducing MLOps - End-to-end ML process를 위한 CD(Continuous Delivery)
머신러닝 프로젝트 구축에 있어 피드백 루프(Feedback loop) 구축은 필수적입니다. 이를 인프라 관점에서 봤을 때 아래와 같은 3가지 구성 요소가 필요합니다.
- 여러 상용 서버에서 데이터를 수집하는 로그 시스템
- 버전 관리 및 모델의 서로 다른 버전 간 평가를 수행하는 모델 평가 저장소
- 챔피언/챌린저(섀도우 테스트) 또는 A/B 테스트를 통해 상용 환경들에서 모델을 비교하는 온라인 시스템
1. 로그 시스템 (Log System)
최근의 인프라 환경은 여러 대의 서버에 여러 모델을 동시에 배포하는 등 복잡해지고 있어 중앙 집중화해서 분석하고 모니터링할 수 있는 환경이 필요합니다. 여기에 모델의 메타데이터, 입력값(데이터 드리프트 감지), 출력값, 시스템 로그, 그리고 모델에 대한 설명이 저장되어 분석에 활용할 수 있어야 합니다.
2. 모델 평가 저장소 (Model Evaluation Store)
데이터 드리프트가 발생하면 모델 성능이 저하되고 있을 가능성이 높습니다. 이때 모델을 재학습해야하는데, 새 데이터로 동일한 모델을 재학습해서 쉽게 해결할 수도 있지만 새 특성을 추가하거나 새로운 알고리즘을 적용해서 해결할 수도 있습니다. 이때 생긴 각 모델 버전별로 평가 결과를 모델 평가 저장소에 저장합니다.
모델 평가 저장소의 두 가지 주요 작업과 저장 정보는 아래와 같습니다.
1) 시간이 지남에 따라 진화되는 논리 모델의 버전 관리
- 특성 리스트
- 특성 전처리 기법
- 알고리즘 및 하이퍼파라미터
- 학습 데이터 세트
- 평가 데이터 세트
- 평가 지표
2) 논리 모델의 여러 버전 간 성능 비교
- 동일한 데이터 세트로 평가한 결과
3. 온라인 평가 (Online Evaluation)
배포된 모델도 실제 데이터를 이용한 평가가 필요합니다. 이는 챔피언/챌린저 혹은 A/B 테스트를 통해 평가할 수 있습니다.
1) 챔피언/챌린저(Champion/Challenger)
- 하나 이상의 추가 모델(챌린저)를 상용 환경에 배포해서 동일한 데이터를 받아 스코어링하는 빙식
- 요청에 대한 응답이나 예측은 반환하지 않음
- 서버 성능 혹은 비용이 2배 이상 소요될 수 있음
2) A/B 테스트
- 기존 모델이 배포된 상황에서 신규 모델을 추가로 배포해 실제 데이터를 나눠서 평가하는 방식
- 챔피언/챌린저 방식을 사용할 수 없을 때만 사용하는 것을 권장
본 게시글은 Introducing MLOps를 읽고 정리한 내용입니다.
댓글남기기