
MLOps 이해관계자들
MLOps는 엔터프라이즈 AI 전략의 핵심이며, 이를 위해 맡는 역할은 직무 전문가, 데이터 과학자, 데이터 엔지니어, 소프트웨어 엔지니어, DevOps 엔지니어, 모델 리스크 관리자/감리인, 머신러닝 아키텍트 7가지가 있습니다.
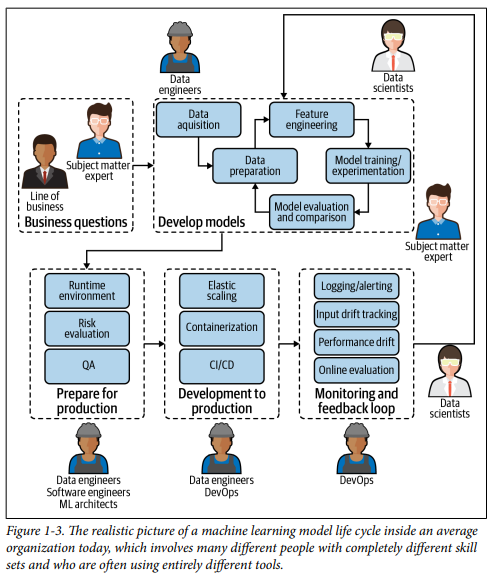 < 출처: Introducing MLOps 원서(https://itlligenze.com/uploads/5/137039/files/oreilly-ml-ops.pdf) >
< 출처: Introducing MLOps 원서(https://itlligenze.com/uploads/5/137039/files/oreilly-ml-ops.pdf) >
직무 전문가(SME, Subject Matter Expert)
다른 역할에 비해 머신러닝에 대한 깊은 이해도는 떨어지지만, 달성해야하는 명확한 목표와 KPI를 제시하고 목표를 달성하는 방향으로 이끌 수 있어야합니다. 특히 데이터 과학자가 머신러닝 모델을 구축하는데 있어 명확한 목표와 방향으로 시작할 수 있도록 해야합니다.
데이터 과학자
직무 전문가가 제기하는 비즈니스 요구사항을 해결하는 모델을 구축하고, 상용 환경에서 운영 가능한 모델을 제공할 수 있어야합니다. 데이터 엔지니어에게 데이터 취합, 준비, 검토를 요청하고 모델 개발, 테스트, 최적화 및 배포 후 지속적인 모델 품질 검사를 진행해야 합니다. 이 부분이 가능하도록 MLOps를 구축할 때 데이터 과학자들의 요구사항을 가장 중요하게 검토해야합니다.
데이터 엔지니어
데이터 과학자가 구축할 머신러닝 모델에 공급하기 위한 데이터를 취합하고 사용하는 부분을 최적화합니다. 특히 직무 전문가와 긴밀하게 협업해서 비즈니스 요구사항 달성에 적합한 데이터를 찾고 사용할 수 있도록 준비해야합니다. 이러한 데이터 파이프라인을 구축했을 때 머신러닝 모델 생애주기(Life Cycle)의 중요한 역할을 맡아 모델 구축 및 모니터링을 뒷받침합니다.
소프트웨어 엔지니어
데이터 과학자가 구축한 머신러닝 모델을 회사의 상용 소프트웨어(혹은 애플리케이션)에 적용합니다. 또한 머신러닝 모델 생애주기를 구축하기 위해 데이터 과학자, DevOps 엔지니어와 협업해서 머신러닝 코딩, 학습, 테스트, 배포 모두 CI/CD 파이프라인에 포함해야합니다. 이외에 소프트웨어 테스트, 버전 관리, 개발 협업 관리 등을 진행해야합니다.
DevOps 엔지니어
MLOps가 DevOps 원치에서 생겨난 만큼 머신러닝 모델 생애주기를 운영 관점에서 가장 중요한 역할을 담당합니다. 첫째는 머신러닝 모델의 보안, 성능, 가용성을 보장하기 위한 테스트 및 운영시스템을 구축하고 운영해야합니다. 둘째는 CI/CD 파이프라인을 관리합니다. 이를 진행하는데 있어 데이터 과학자, 데이터 엔지니어, 데이터 아키텍트와의 긴밀한 협업이 필요합니다.
모델 리스크 관리자/감리인
모델 리스크 관리(MRM, Model Risk Management)를 진행하여 리스크 감소를 목적으로 결과물을 분석해 초기에 소프트웨어(혹은 애플리케이션)가 리스크를 내포하거나 유발하지 않도록 해야합니다. 또한 자세한 성능 뿐만 아니라 데이터 출처도 확인해 리포팅해야합니다.
머신러닝 아키텍트
기존의 데이터 아키텍트의 역할(데이터의 저장과 소모 방식 등)뿐만 아니라 머신러닝 모델 파이프라인에 대한 확장성있고 유연한 환경을 보장해야합니다. 또한 팀이 기술적 전문성을 확보할 수 있도록하여 머신러닝 모델의 성능을 향상시키기 위한 새로운 기술을 도입할 수 있어야합니다. 이를 위해 기술 전문가(데이터 과학자, 데이터 엔지니어, 소프트웨어 엔지니어, DevOps 엔지니어)와 긴밀하게 협업해야합니다.
본 게시글은 Introducing MLOps를 읽고 정리한 내용입니다.
댓글남기기